AMD RDNA 4 architecture deep dive: A 64-CU monolithic design with all-round improvements to compute, media encode-decode, ray tracing, and AI

AMD offered a sneak peek into RDNA 4 at CES 2025 and confirmed the arrival of the Radeon RX 9070 XT and the RX 9070, but did not even offer a passing remark about the new architecture during the actual keynote.
The company, however, maintained that more information on RDNA 4 and the new Radeon GPUs would follow soon, and here we are.
Today, AMD takes the wraps off RDNA 4 and the new Radeon RX 9070 series GPUs. The RX 9070 series will be officially available in retail stores from March 6 with performance reviews landing a day before.
AMD RDNA 4: Back to a monolithic design
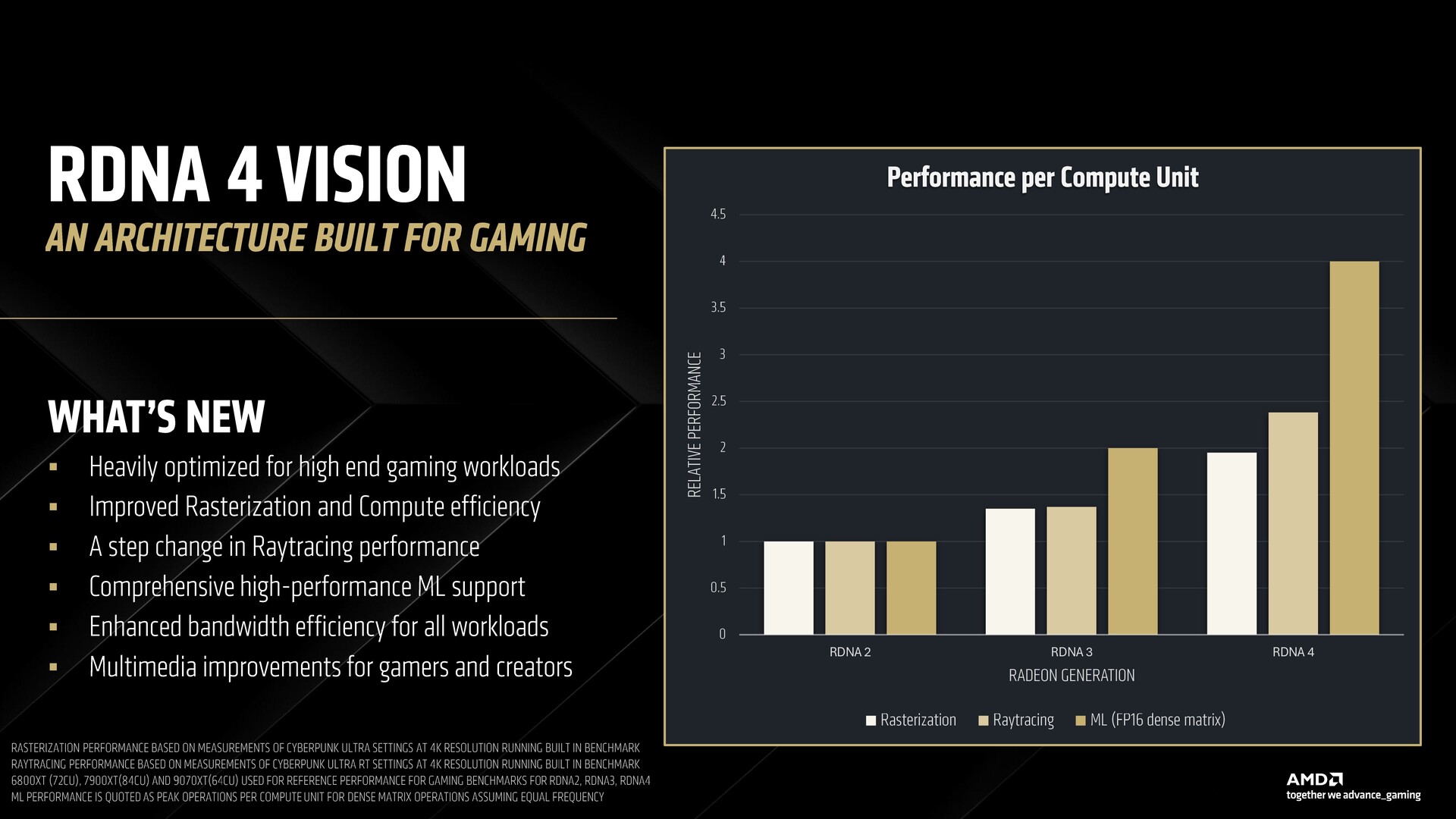
RDNA 4 builds on the goals AMD had set itself with RDNA 3. According to AMD, RDNA 4 is designed to cater to heavier gaming workloads with a focus on improved raster performance and efficiency.
Then there are the customary improvements to ray tracing pipelines as well along with renewed focus on AI capabilities and media encode/decode.
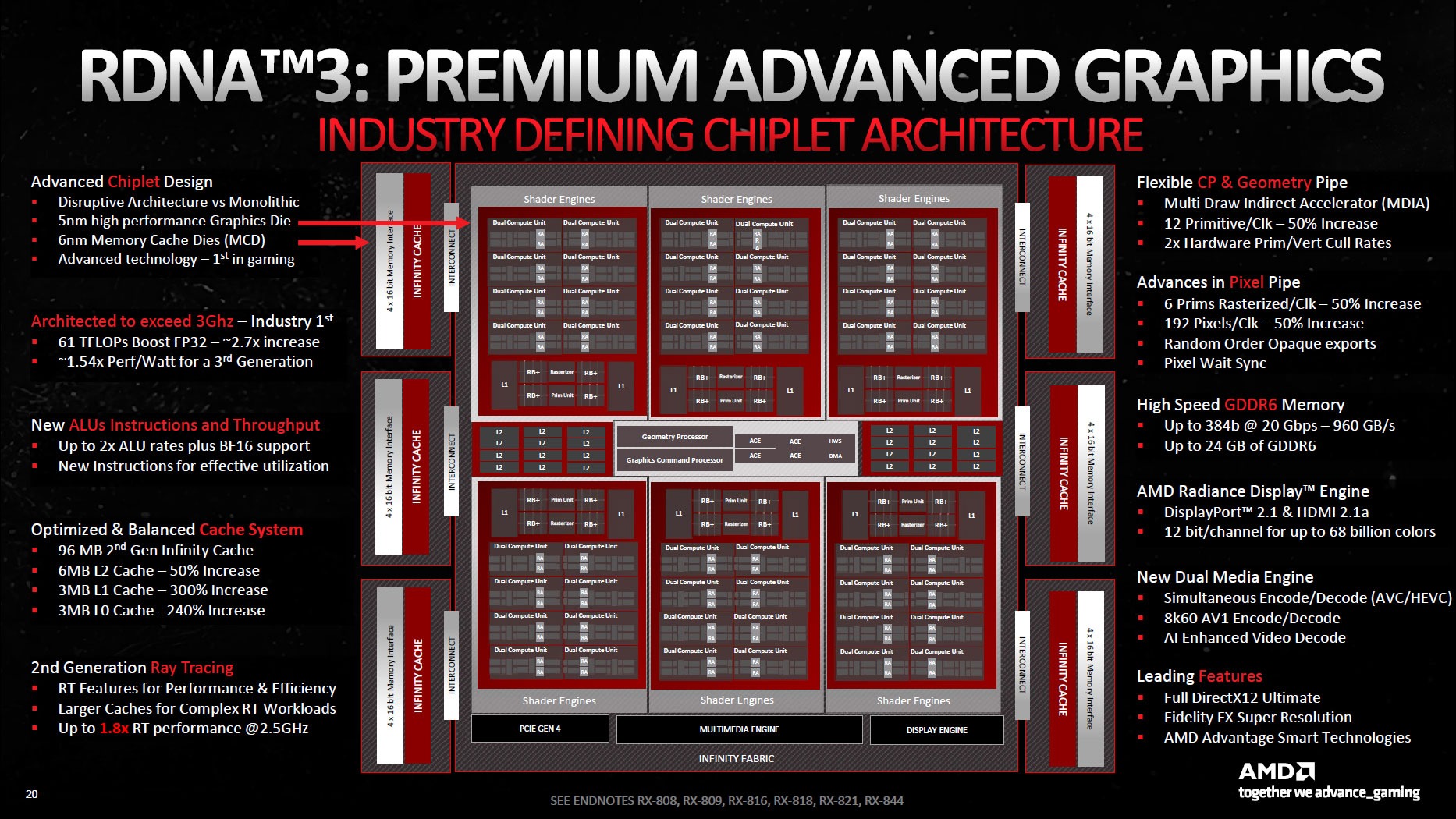
RDNA 3 saw the advent of a chiplet design for GPUs taking inspiration from Ryzen processors. Here, we saw the separation of memory cache dies (MCDs) from the graphics compute die (GCD).
With RDNA 4, however, AMD is going back to the traditional monolithic design. The components are essentially the same, but there are no MCD-GCD interconnects as the memory and compute are now directly interfaced by the Infinity Cache.
The RDNA 4 GPU, the Radeon RX 9070 XT in this case, features four shader engines with eight workgroup processors (WGPs) each. Each WGP is comprised of a total of eight compute units (CUs) for a total of 64 CUs.
AMD says that the new compute units are now more capable than ever enabling improved ray tracing, double the peak throughput, support for latest matrix acceleration capabilities with broader numeric format support.
New to the RDNA 4 CU, and one that we've seen with the Tensor cores in Nvidia's Ampere architecture, is support for structured sparsity that allows for faster matrix operations, especially in cases when many of the weights are zero.
We also get to see improvements to the memory subsystem. The L2 cache gets an increase from 6 MB in RDNA 3 to 8 MB in RDNA 4 while the Infinity Cache gets upgraded to 3rd gen but drops to 64 MB from 96 MB in RDNA 3.
AMD continues to rely on GDDR6 memory with the new generation. Both the RX 9070 XT and the RX 9070 offer a 384-bit 16 GB GDDR6 memory interface clocked at 20 Gbps for an effective 640 GB/s bandwidth. This is much lower than the 960 GB/s bandwidth offered by RDNA 3, but AMD says RDNA 4's video memory specifications were chosen carefully to support current and future titles.
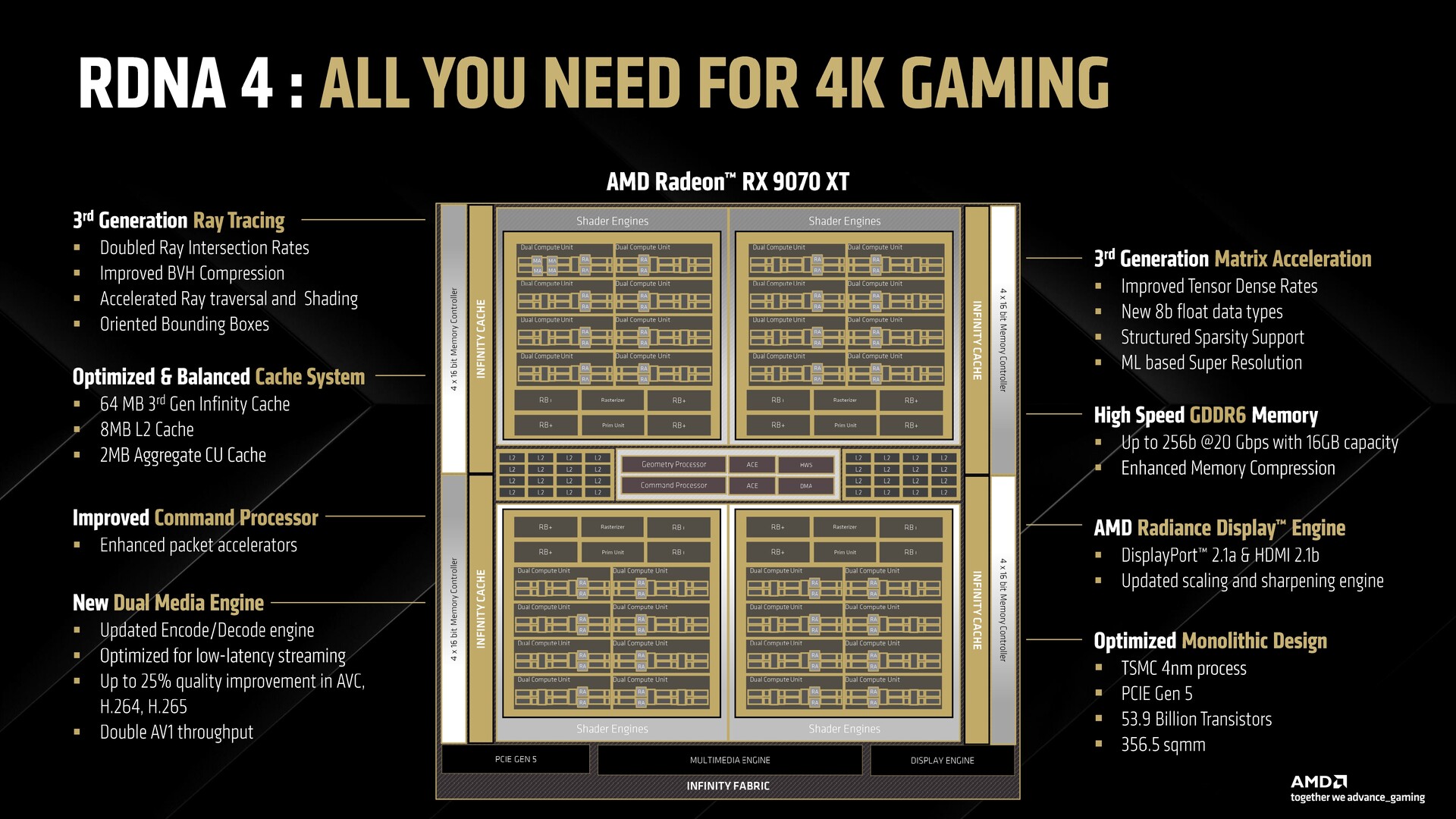
Improved media engine and hardware flip metering support
Video encoding was one of the major pitfalls with RDNA 3, and AMD promises significant improvements in this regard. The company promises major improvements in H.264 and AV1 encoding and less blocking artefacts for the same amount of data.
The improvements extend to video decode as well, with reduced power consumption and increased performance while decoding formats like AV1 and VP9.
The Radiance Display Engine now consumes a lot less power in dual-monitor FreeSync configurations. Also new is support for hardware flip queue in Windows Display Driver Model (WDDM) 3.0 for video playback.
This frees up CPU resources by offloading frame scheduling to the GPU. The multi-frame generation (MFG) technology in Nvidia Blackwell GPUs also relies on hardware flip metering.


A look at the RDNA 4 compute unit
At the outset, the structure of an RDNA 4 CU isn't that different from what we've seen with RDNA 3. However, there are performance and efficiency improvements in each of the CU components.
WMMA (Wave Matrix Multiply Accumulate) operations have been enhanced to meet the requirements of the new hardware. Scaler units get upgrades to handle Float32 operations. The scheduler can split and process a large compute workload into split and named barriers.
AMD said that RDNA 4 is built to cater to new rendering techniques that developers use in today's games. While upscaling has been in vogue, effective path tracing requires ML acceleration as part of the rendering process itself and not as an afterthought.
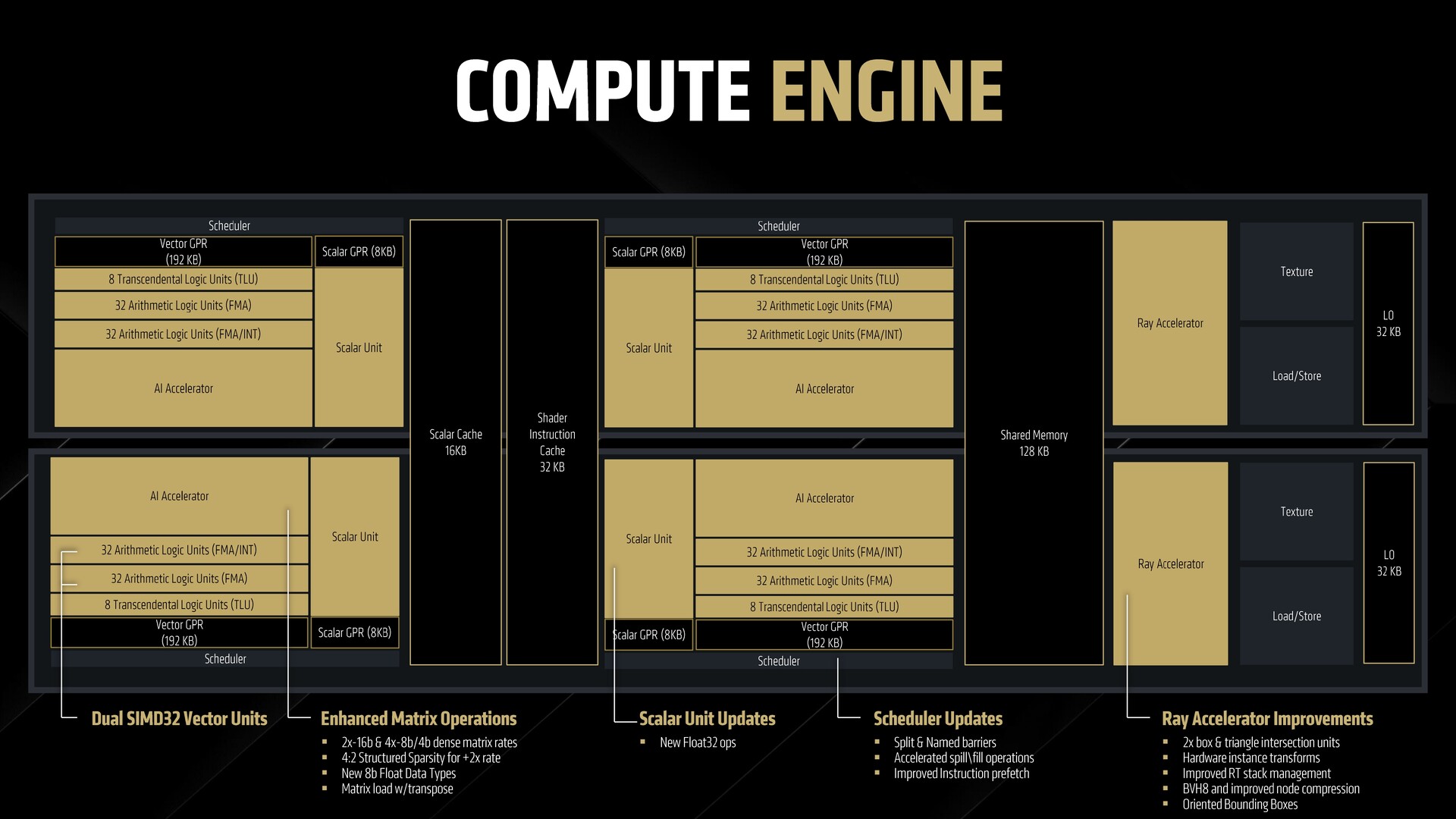

Ray accelerators in RDNA 4
RDNA 4 offers 64 3rd gen ray accelerators in the RX 9070 XT. The structure of a ray accelerator in RDNA 4 is similar to that in RDNA 3 but includes an additional intersection engine for 2x the number of ray box and ray triangle units.
There's also a dedicated hardware ray transform that alleviates the need to use shader instructions to do the job, thus minimizing ray traversal overhead. A 128 KB memory in each dual CU helps hold the ray stack for efficient push and sort operation.
RDNA 4 introduces the concept of oriented bounding boxes (OBBs) that aligns BVH bounding boxes to the geometry, thereby minimizing false-positive ray interactions in what is otherwise just empty space in a box. AMD says this approach can improve ray traversal performance by as much as 10%.
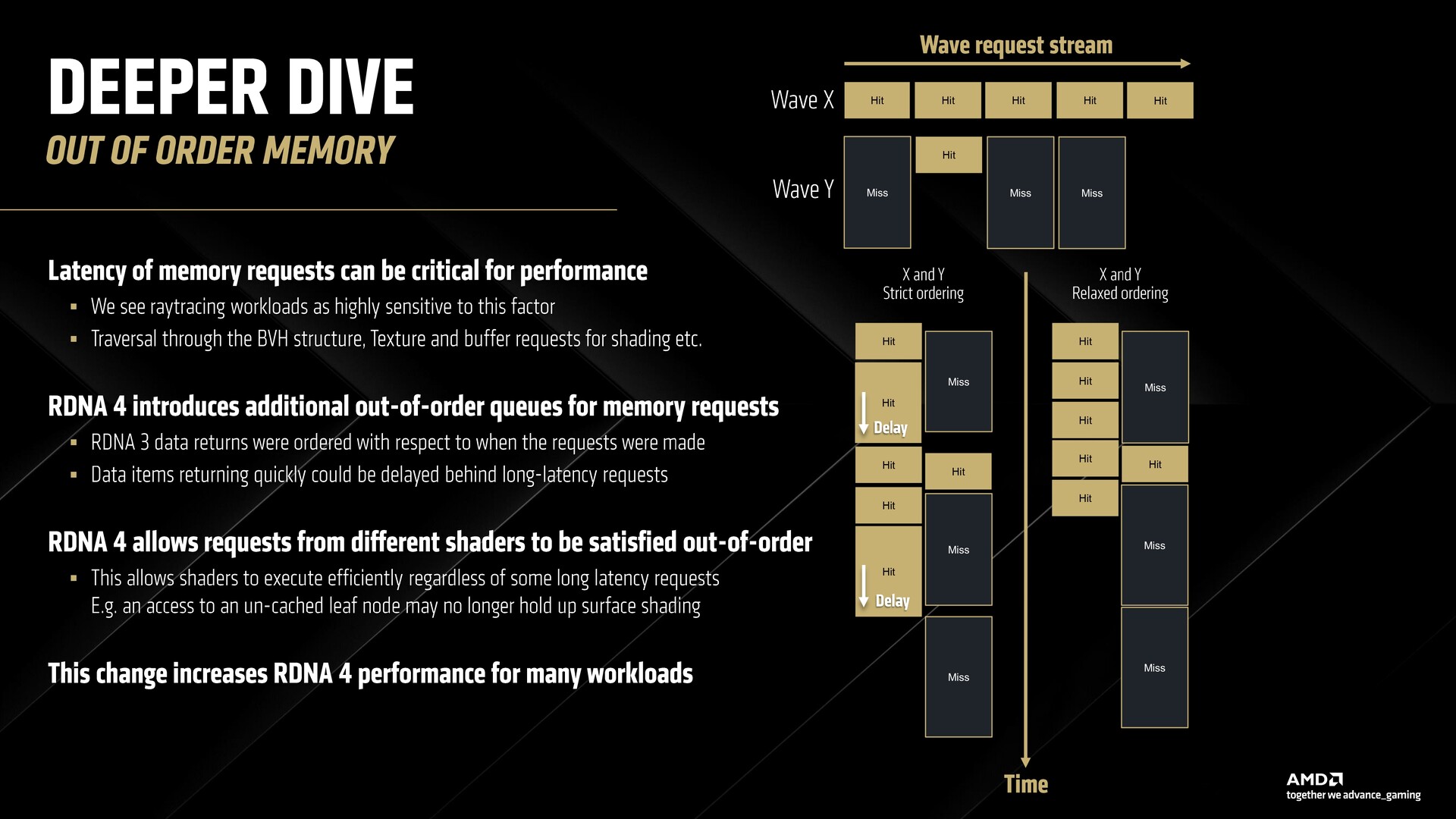
Also new this time is support for relaxed out-of-order memory requests that efficiently reduces the wait time for waves that have missed hitting the high-level cache sooner. This not only improves ray tracing but other workloads as well.
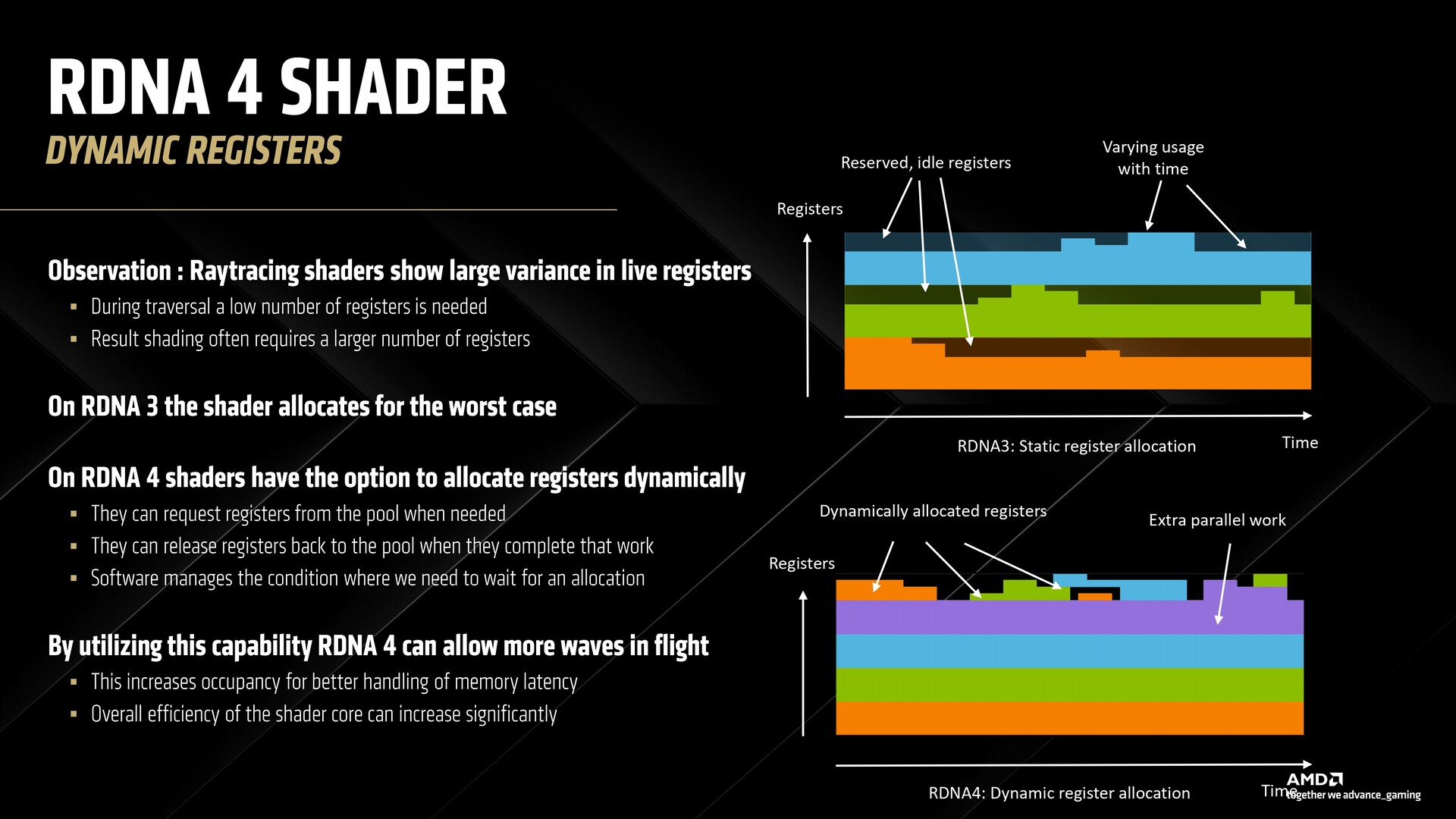
In RDNA 4, shaders can dynamically allocate registers that allows accommodating more waves in flight with improved memory latency.



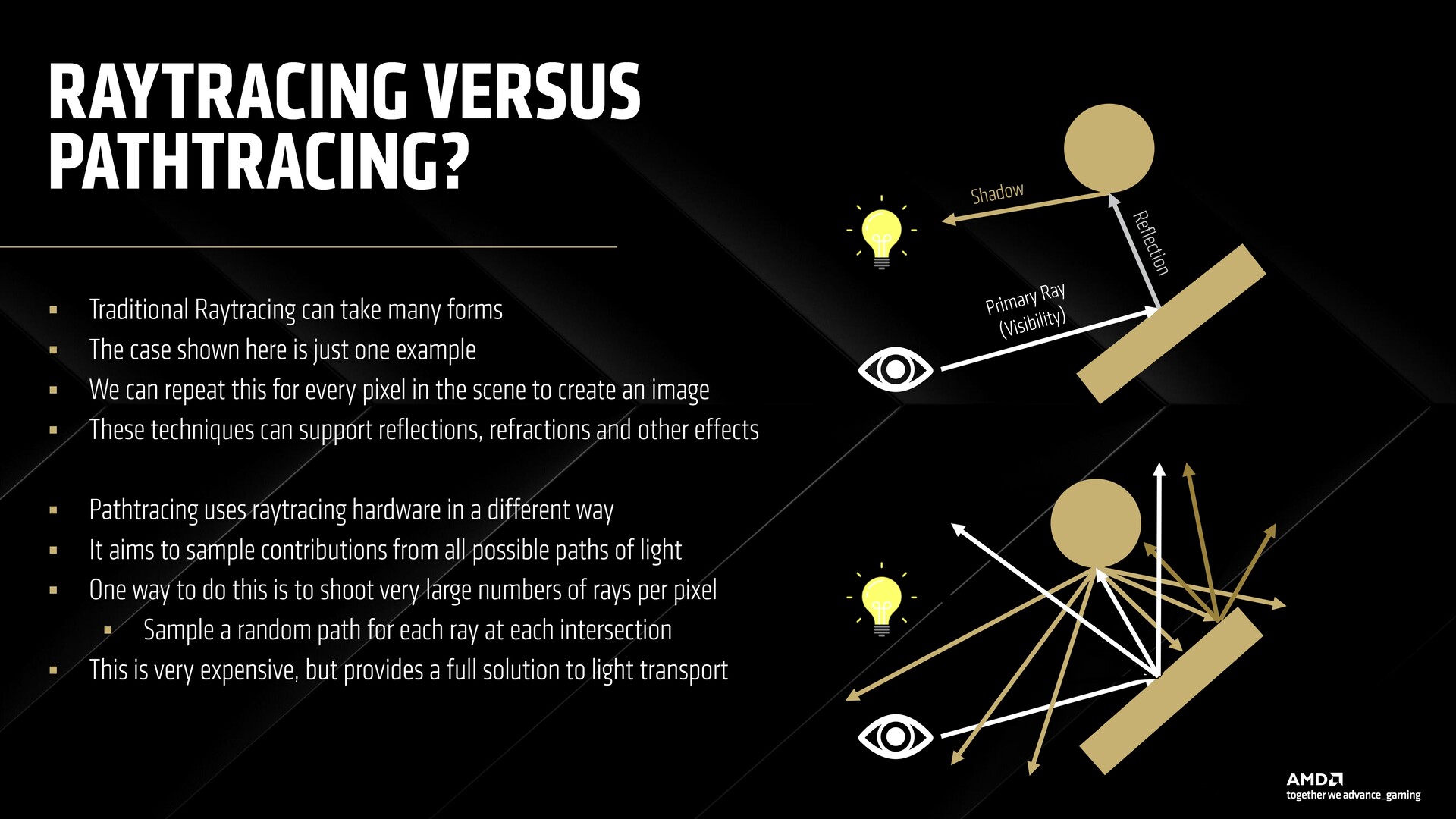
Path tracing with RDNA 4
AMD cards have struggled with ray tracing in general, so path tracing seemed out of the equation even with top-end RDNA 3 cards. RDNA 4 aims to change that with support for neural radiance caching along with a new neural supersampling, and denoising model.
AMD hasn't provided exact performance numbers for path tracing enabled titles, but we should be getting an idea while reviewing these cards.




AI capabilities built on Radeon and Instinct
AMD said that RDNA 4 features dedicated math pipelines for ML acceleration focused on high performance with narrower data types. New to RDNA 4 is support for FP8 and BF8 for high performance, high precision inference.
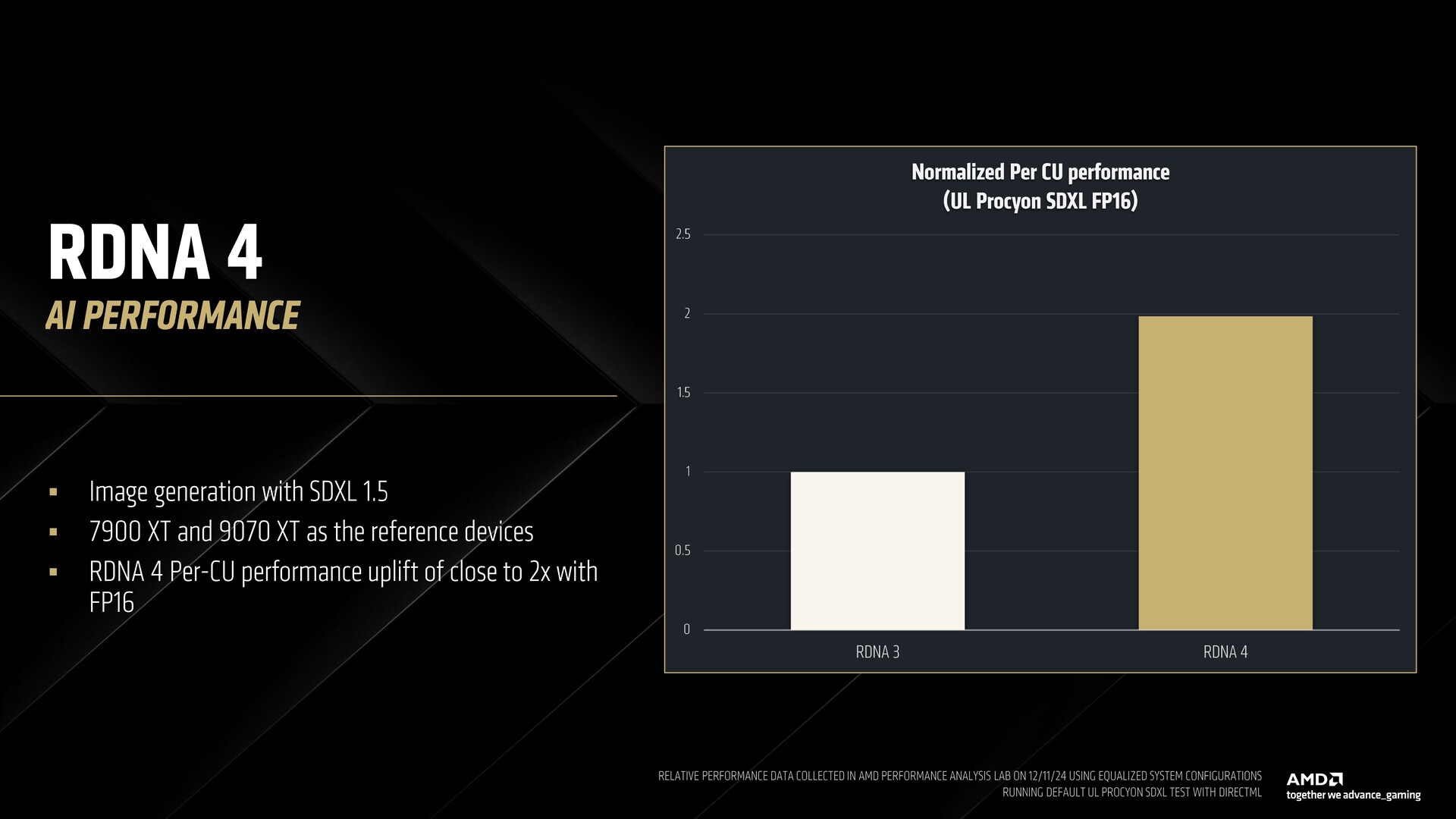
Demonstrating SDXL 1.5 image generation, AMD showed how the RDNA 4-based Radeon RX 9070 XT offers double the FP16 performance per CU compared to the RDNA 3-based RX 7900 XT.
Leveraging RDNA 4's new AI capabilities is FSR 4, which is an end-to-end pipeline trained on AMD GPUs. FSR 4 uses FP8 for optimal use of bandwidth, performance, and power.
AMD showed up to 3.7x fps improvements with FSR 4 when combined with frame interpolation and Radeon Anti-Lag while maintaining high image quality.



Source(s)
AMD Press Brief
