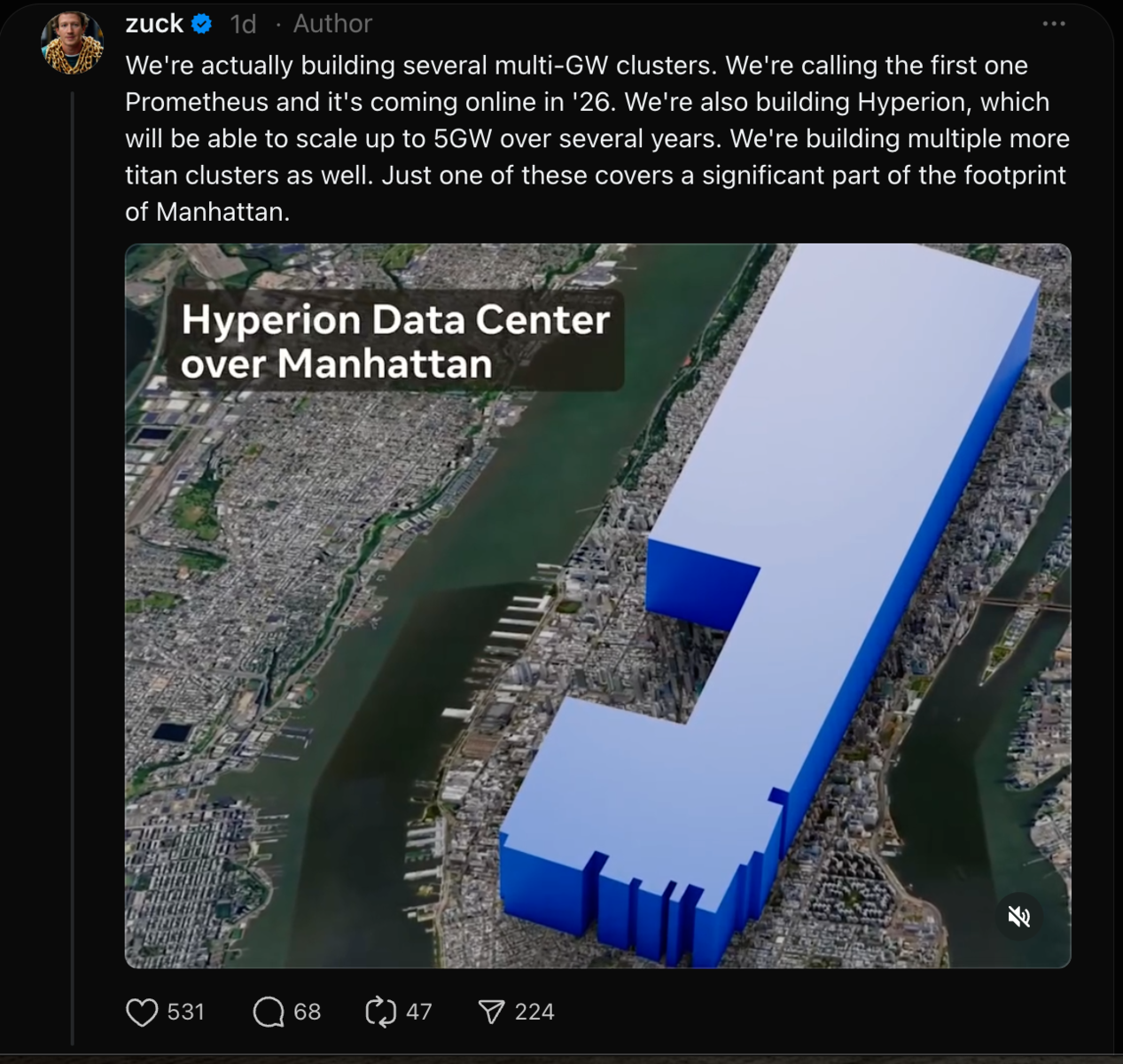
Meta plans AI cluster that's almost the size of Manhattan

Meta is committing a lot of capital to physical infrastructure, announcing a series of "multi-gigawatt clusters" that dwarf its existing server farms. The first site, Prometheus, is scheduled to deliver one gigawatt of power capacity in 2026, while a second project, Hyperion, is designed to scale to five gigawatts over several years. Chief executive Mark Zuckerberg said several additional "titan clusters" are already on the drawing board, each occupying a footprint comparable to a sizable slice of Manhattan.
The spending push answers an industry-wide race for computational heft even though few firms have solved the profitability question for large-scale AI. Meta can fund the build-out from a core advertising business that generated almost $165 billion last year, and it has lifted planned 2025 capital expenditure to a range of $64 billion to $72 billion. In April, the company consolidated its machine-learning teams under a new banner, Superintelligence Labs, aiming to translate the hardware investment into fresh revenue streams from products such as the Meta AI assistant, image-to-video ad tools, and smart-glasses software.
Instead of conventional roofed halls with redundant diesel backup, the upcoming facilities will rely on "tented" structures, pre-fabricated power-and-cooling modules, and on-site substations. Eliminating some redundancy trims cost and months off the schedule. Meta is also installing two 200-megawatt natural gas plants in Ohio to supplement grid supply.
Talent has become the other pillar of the plan. Over recent weeks Zuckerberg has personally lured high-profile engineers and researchers, including former Scale AI chief executive Alexandr Wang and ex-GitHub leader Nat Friedman, after investing $14.3 billion in Scale. Inside Superintelligence Labs, teams are debating whether to abandon Behemoth-Meta's most powerful open-source model-in favor of a closed alternative that could differentiate the business from rivals.
Analysts view the venture as a long-term bet on leadership in AI computing. A single gigawatt-class cluster would exceed three billion tera-FLOPS and give Meta more processing per researcher than any peer lab. Realizing that edge, however, will require flawless execution on power delivery, supply chain, and model development-and patience- because monetization may arrive well after the hardware is in place.
Source(s)
Reuters (in English)
