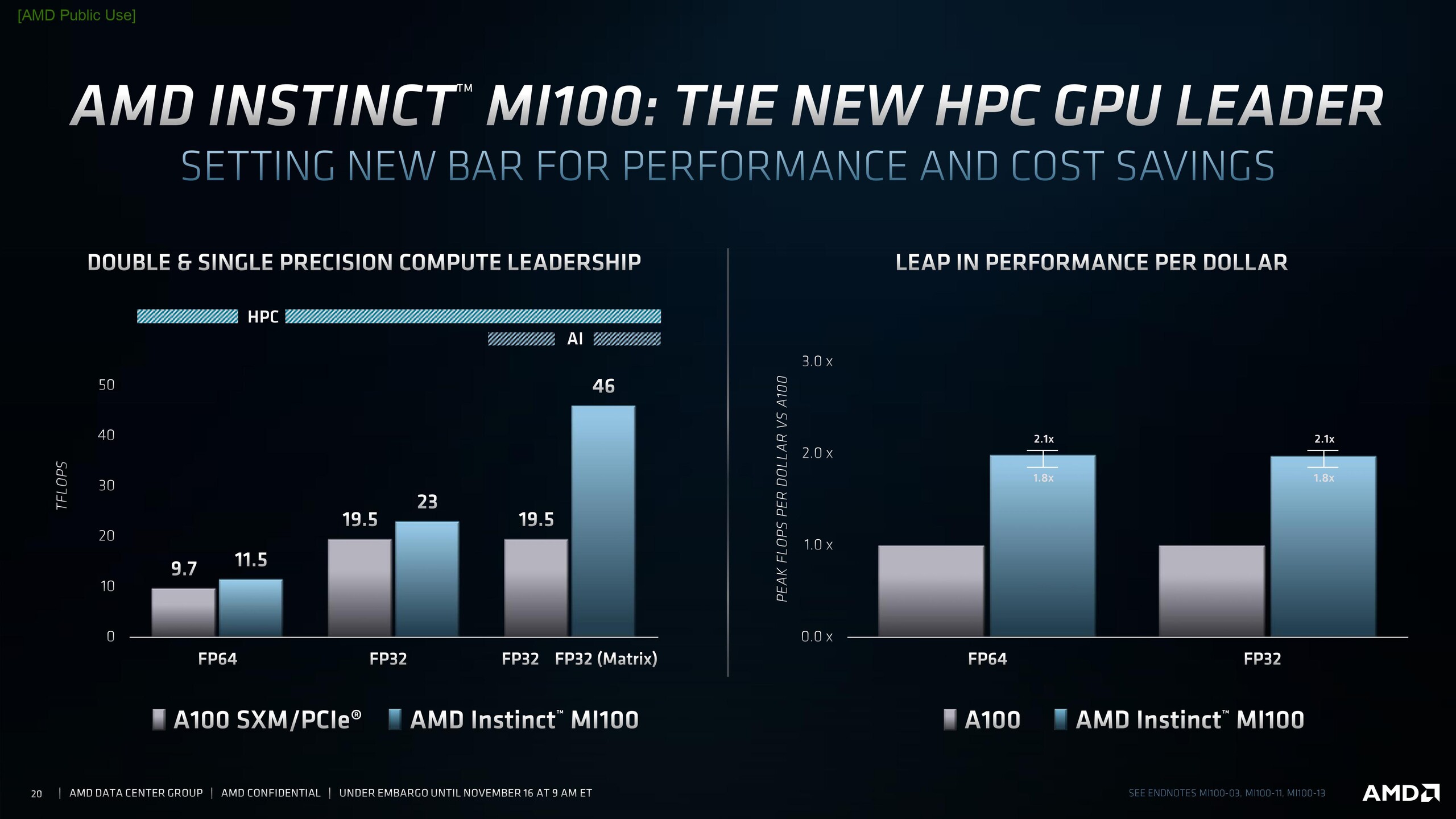
AMD announces CDNA-based Instinct MI100 GPU with 120 CUs for HPC, promises up to 2.1x more performance per dollar compared to the NVIDIA A100

AMD has announced the Instinct MI100 based on the new CDNA architecture targeted at machine learning (ML) and high performance computing (HPC) workloads. The MI100 is slated to offer 10 teraflops of FP64 performance that goes up to 11.5 TFLOPS when paired with second gen AMD EPYC processors.
During the presentation, AMD also confirmed that the 3rd gen EPYC processors based on Zen 3 codenamed Milan are now being sampled to select OEMs and are slated for a Q1 2021 launch.
AMD said that it is developing different architectures tailored for specific applications with some overlap. While RDNA will cater to gaming, CDNA is more focused towards compute and HPC applications. The Instinct MI100 offers a Matrix Core Technology that enables single and mixed precision matrix operations such as FP32, FP16, bFloat16, Int8, and Int4.
The second gen Infinity Fabric in the MI100 features 32 GB of HBM2 memory at 1.2 GHz delivering 1.23 TB/s of bandwidth.
The following table illustrates the specifications of the AMD Instinct MI100:
| Design | Full-height, Dual-slot, 10.5 in. long |
| Compute Units | 120 |
| Stream Processors | 7,680 |
| FP64 TFLOPs (Peak) | 11.5 |
| FP32 TFLOPs (Peak) | 23.1 |
| FP32 Matrix TFLOPs (Peak) | 46.1 |
| FP16/FP16 Matrix TFLOPs (Peak) | 184.6 |
| Int4/Int8 TOPS (Peak) | 184.6 |
| bFLOAT16 TFLOPs (Peak) | 92.3 |
| HBM2 ECC Memory | 32 GB |
| Memory Interface | 4,096-bit |
| Memory Clock | 1.2 GHz |
| Memory Bandwidth | 1.23 TB/s |
| PCIe Support | Gen4 |
| Infinity Fabric Links/Bandwidth | 3 / 276 GB/s |
| TDP | 300 W |
| Cooling | Passively cooled |
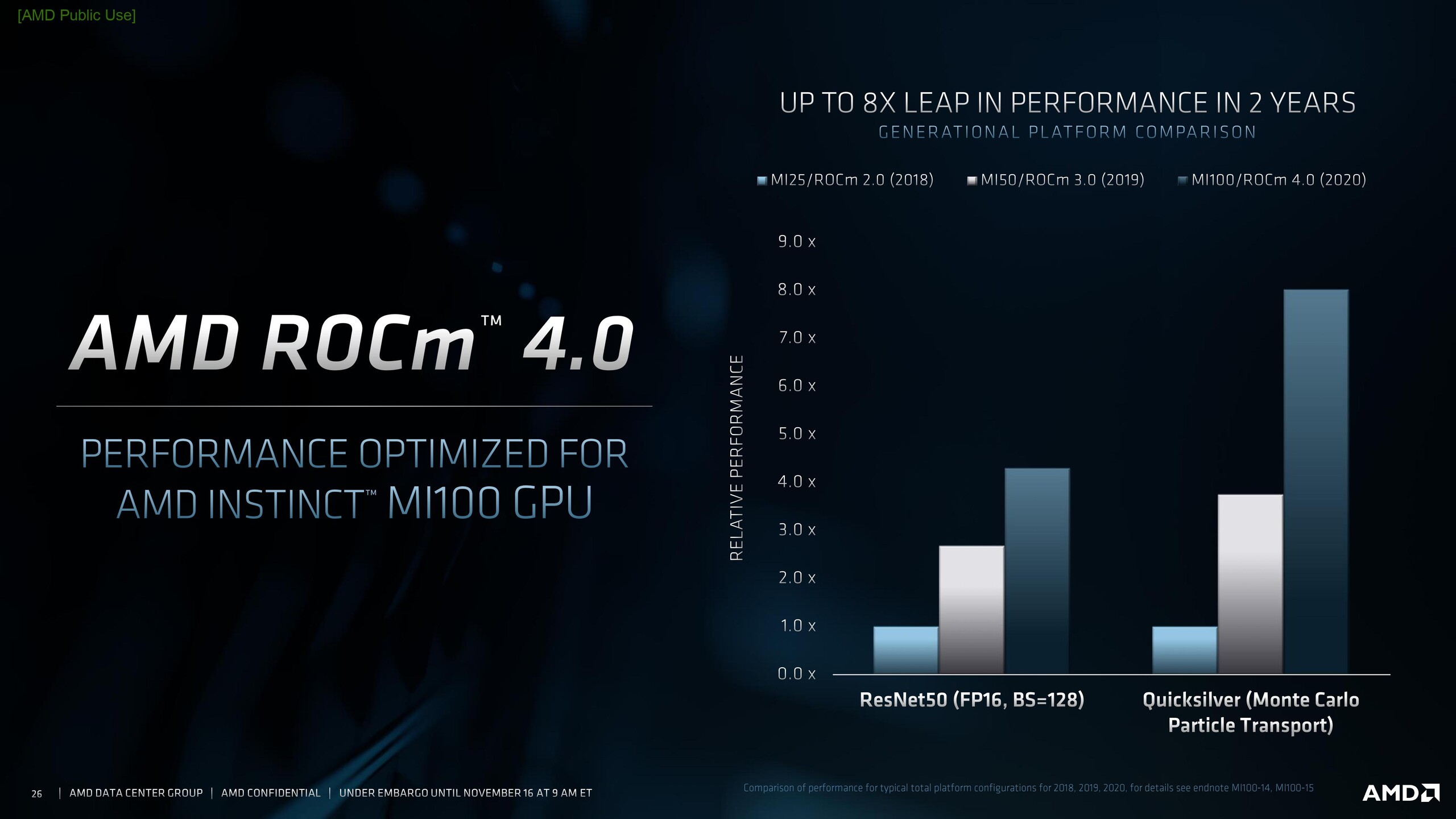
While the MI100 is designed to work well with EPYC processors, AMD confirmed that the new GPU supports Intel processors as well. Overall, up to 7x FP16 performance can be expected from the MI100 compared to previous generation AMD HPC GPUs.
The Instinct MI100 delivers up to 64 GB/s of Infinity Fabric bandwidth between the CPU and the GPU without the need to use any PCIe switches. There are a total of three Infinity Fabric links that offer up to 276 GB/s throughput. Essentially, a quad-GPU hive of the MI100 can yield up to 1.1 TB/s of total bandwidth. According to AMD, these features give the MI100 significant leads over the NVIDIA A100 in FP16/FP32 loads while also offering higher performance per dollar (see slides below).
The Instinct MI100 supports the new ROCm 4.0 ecosystem, which AMD pegs as a complete exascale solution for ML and HPC workloads. ROCm 4.0 now uses an open source compiler and supports OpenMP 5.0 and HIP. Additionally, PyTorch and TensorFlow are now optimized for ROCm 4.0.
The AMD Instinct MI100 can be expected this year end in major OEM and ODM systems from the likes of Dell, Gigabyte, HP, and SuperMicro.






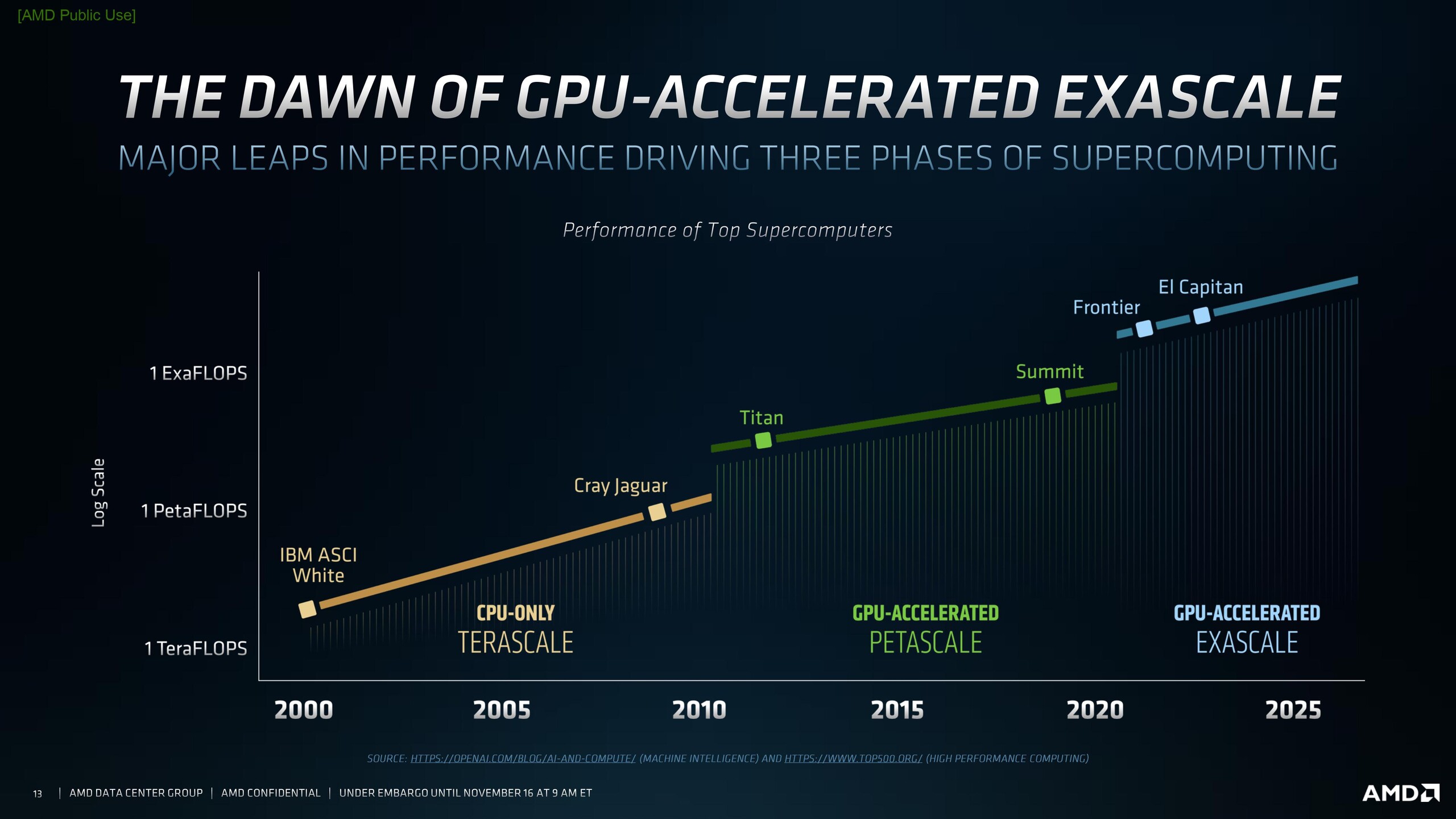
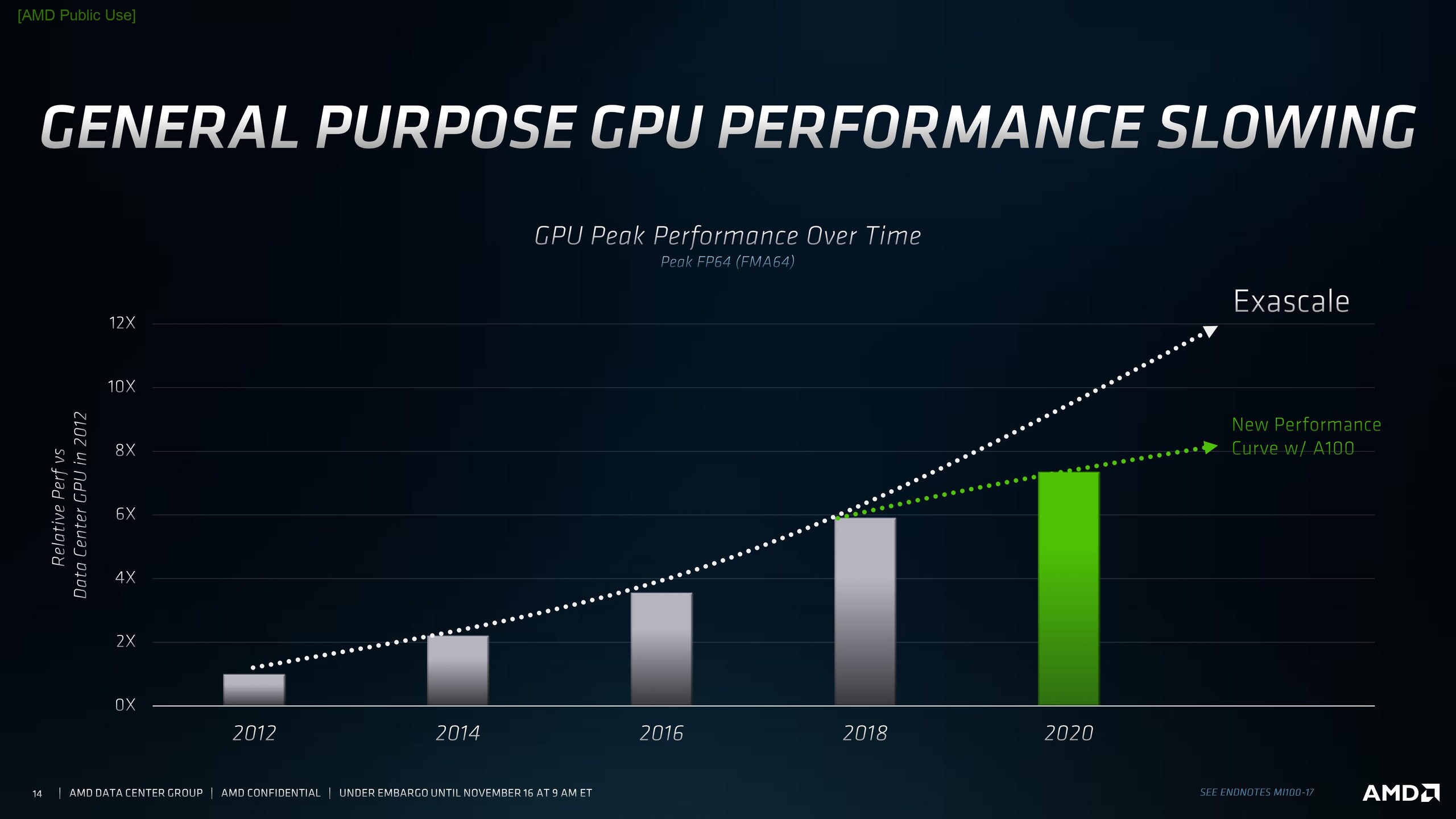
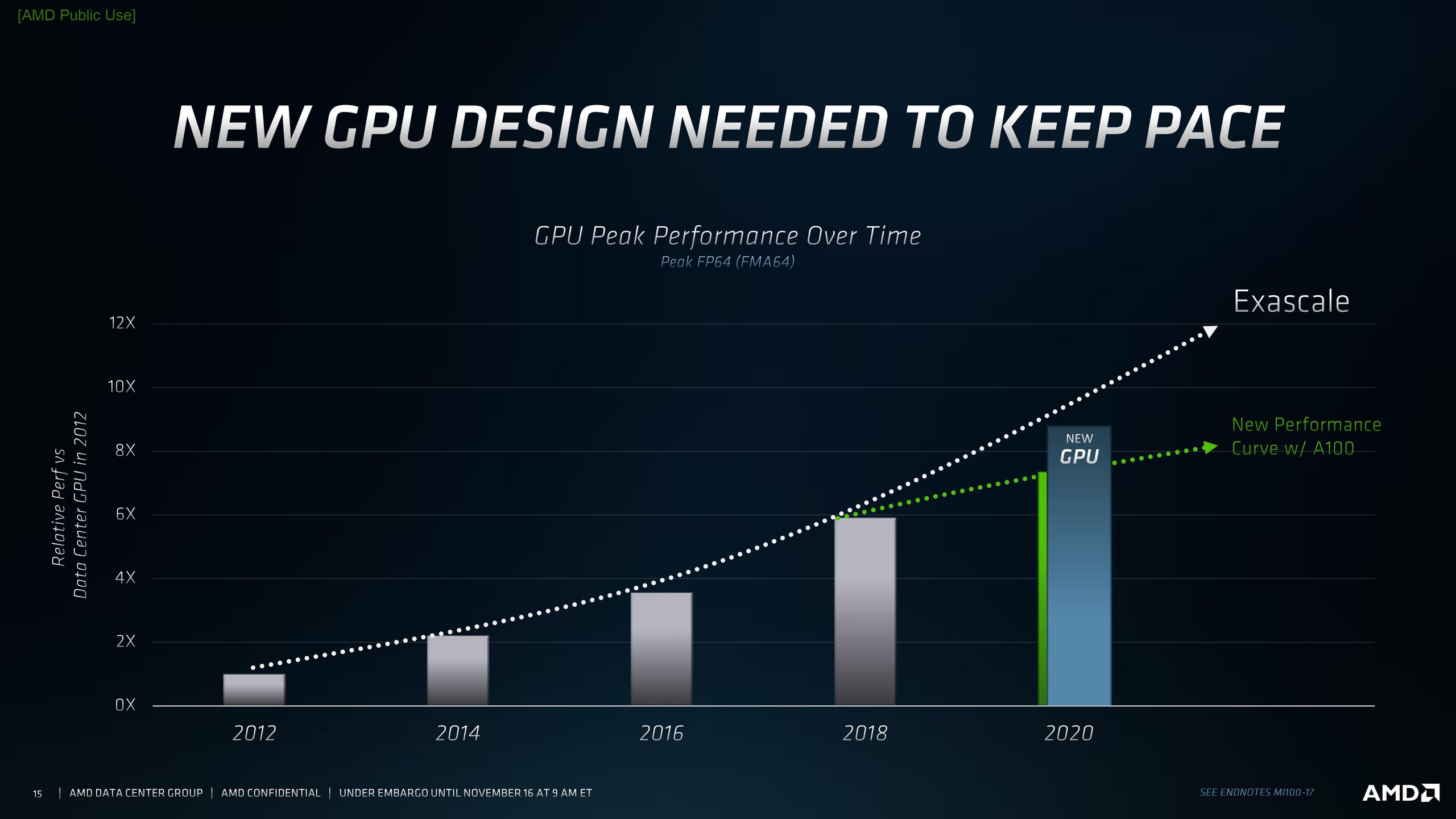
Here are some of the slides from AMD's press briefing.












Source(s)
AMD Press Release
