Researchers enable Nvidia CUDA app support on RISC-V GPGPU
Nvidia first introduced CUDA (Compute Unified Device Architecture) support for its GPUs back in 2007, allowing graphics cards to work as a powerful CPU or general purpose GPU (GPGPU) and run compute instructions. Since then, Nvidia started to add CUDA-enabled small cores to all of its GPUs, and CUDA evolved into a complex parallel computing platform / API that can power even the fastest supercomputers in the world. It is a proprietary solution, so it does not work with AMD or Intel GPUs. However, this has not stopped researchers from trying to port the platform to a RISC-V-based GPGPU, and it looks like CUDA can be adapted to run on non-proprietary hardware after all.
RISC-V emerged as one of the best alternatives for ARM’’s solutions ever since Nvidia initiated the ARM acquisition deal. As the premiere open-source / license-free instruction set architecture, RISC-V can even be programmed to work as an alternative to the x86 architecture on desktop / laptop PCs, and Intel is already planning a RISC-V collaboration for future mobility processors. Researchers from the U.S. and South Korea recently made use of the easy to understand syntax and extensive customization of the RISC-V ISA to enable CUDA support on a GPGPU project called Vortex. The RISC-V hardware used in this case relies on the RV32IMF ISA, which allows 32-bit cores to scale from 1-core to 32-core GPU designs. Vortex already supports OpenCL 1.2 just like AMD’s GPGPUs, but researchers wanted to prove that it can also support CUDA to some extent.
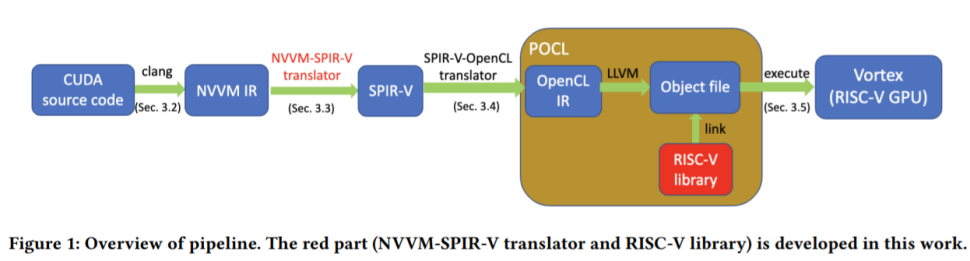
In order to run CUDA-optimised code, the researchers reformulate it in the NVVM intermediate representation (IR) format that is based on open-source LLVM IR. This in turn is further converted to the Standard Portable IR (SPIR-V), which is then translated through the POCL (portable OpenCL) implementation that includes the RISC-V library. Vortex ultimately executes CUDA-optimised code as OpenCL instructions.
Vortex currently supports most CUDA applications, but researchers specify that there are a few applications that use either texture memory or mathematical functions, which are not yet supported. It is still unclear how fast the CUDA to OpenCL translation is realized.
Buy the SiFive HiFive1 Rev B RISC-V SoC and dev board on Amazon
Source(s)
