OpenAI launches faster, improved GPT-4o AI with ability to chat using audio, images, and text

OpenAI has launched a faster-responding, improved GPT-4o (or omni) AI model with the ability to chat using audio, images, and text for input and output. Of note, the AI has noticeably improved speech recognition across a variety of languages besides widely used English and Chinese. For developers, the GTP-4o model is half the price and twice as fast compared to GPT-4 Turbo.
AI chatbots like ChatGPT or CoPilot use AI models that have been trained on millions, even billions of input files that include audio, images, and text. By doing so, the AI learns to recognize certain patterns and connections between all of the input. For example, if the AI sees “First Amendment”, it soon learns that it is related to “freedom of speech” topics. When a model is asked about “freedom of speech” later on, it will recall “First Amendment” as a related element.
ChatGPT runs on OpenAI models that have been progressively improved over the years since inception. Along with competing AI models such as Microsoft CoPilot and Google Gemni, ChatGPT can answer general questions, explain topics, summarize text, write essays, and do much more when prompted. An AI model’s knowledge and know-how comes from the billions of pieces of data that it has been trained on, and its ability to answer prompts correctly depends on the algorithms it uses and model tuning it has received.
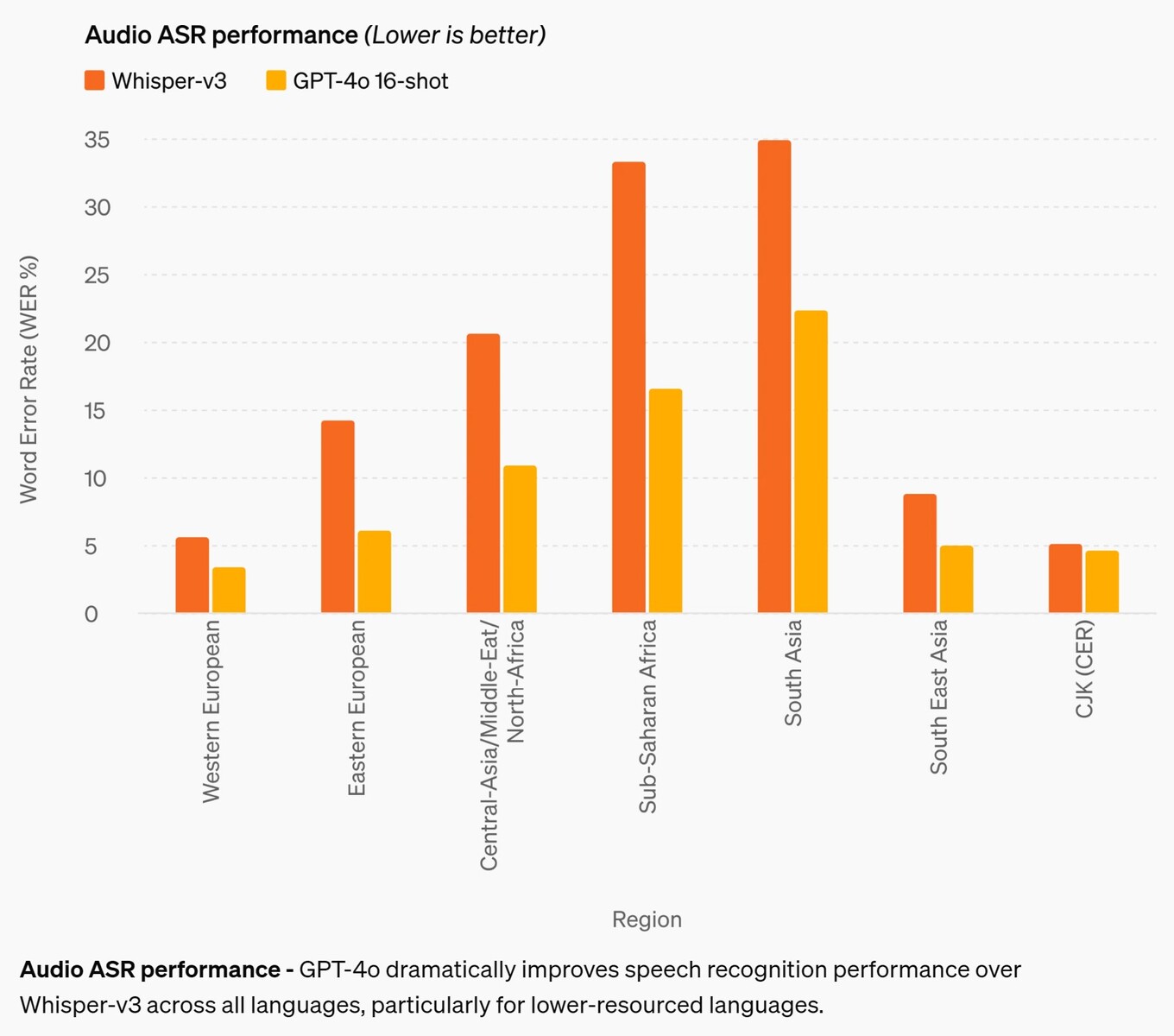
The most significant improvement is its speech recognition accuracy. Although prior AI models are quite decent in English and Chinese, they performed poorly in African, Eastern European, Middle Eastern, and South Asian languages. GPT-4o improves recognition performance by up to approximately 50% in some languages, but still has a long way to go. For example, South Asian languages still have a word error rate (WER) of approximately 22%, or about 1 out of every 5 words spoken. Notably, WER for Western European and Chinese-Japanese-Korean languages is still 3-5%, or about 1 word error for every 20 words spoken. This performance still lags behind that of children of junior high school age. (And sadly, GPT-4o still does not understand dogs.)
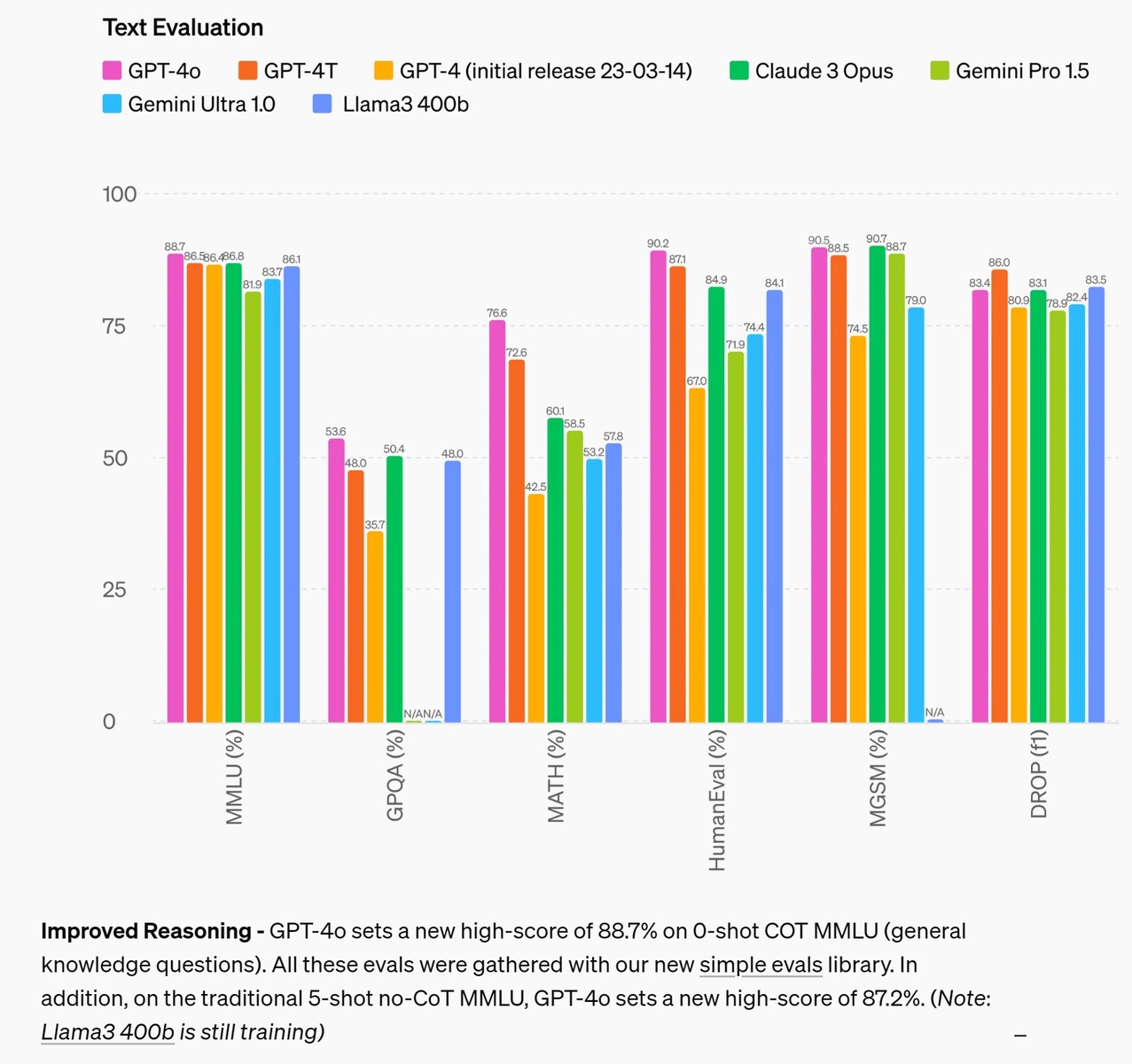
In the area of reasoning, GPT-4o improves upon competing models by up to 4% in most tests to being beat by up to 2.6% in two tests. This suggests that feeding AI more input data alone won’t improve an AI’s ability to reason, so research into other means is needed. In the area of audio translation, GPT-4o barely improves upon Google Gemni performance, suggesting the same.
In the area of answering standardized test questions at the high school student level, GPT-4o manages to achieve a B-grade (80%+ accuracy) only in Afrikaans, English, and Italian, while otherwise performing like a C-grade student in other languages like Chinese. The AI did even worse with questions that required it to refer to a visual figure or diagram to answer the question regardless of language.
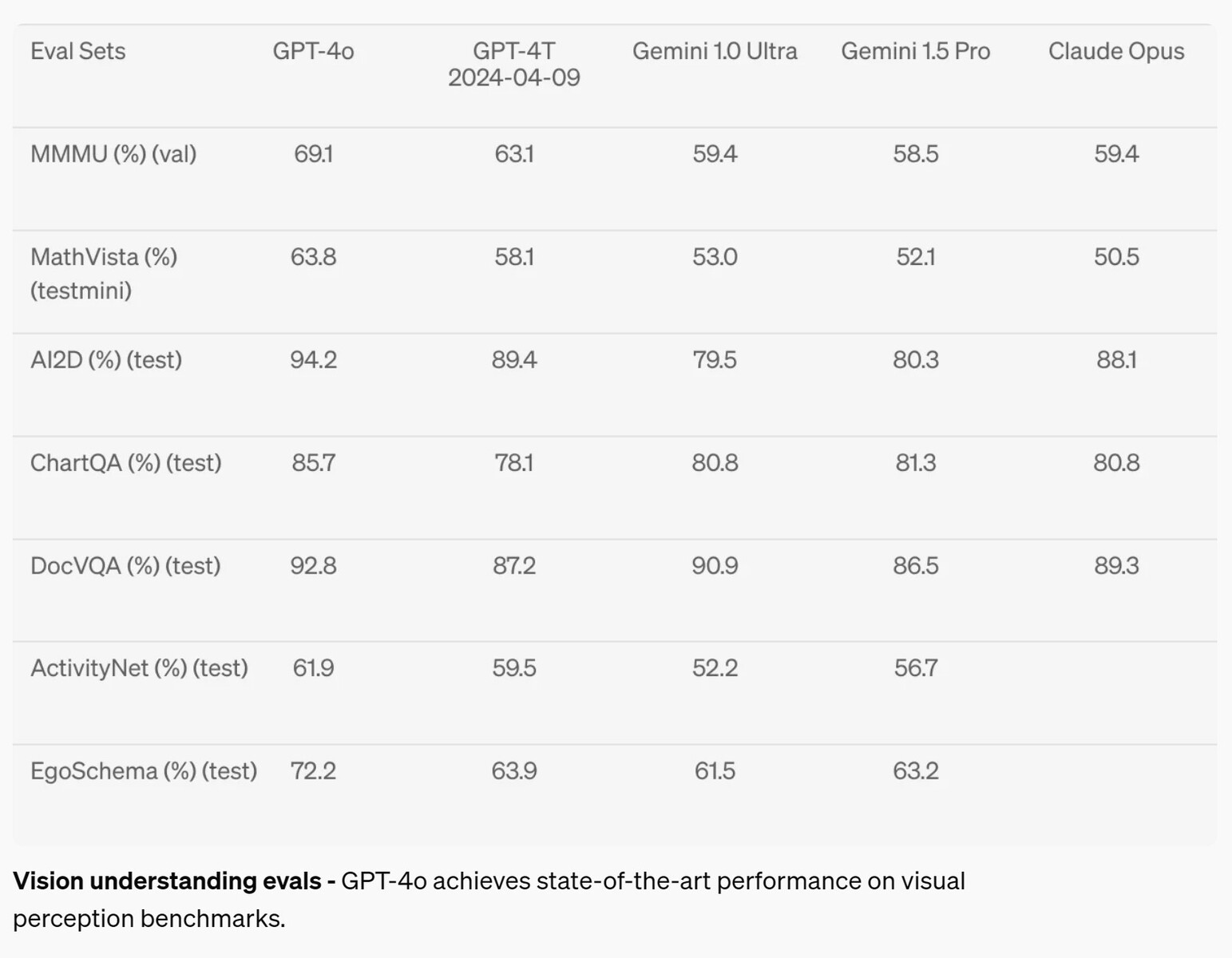
In the field of visual perception, such as understanding diagrams, GPT-4o improved 2 to 10.8% over competing AI models across seven tests, but only reached the A-grade level (above 90%) in just two tests. Math remains a very good test of AI capabilities, and the AI failed with a 63.8% score on the MathVista test on questions that can be answered by a high-school graduate.
The chatbot is available for use today to free and paid users, however, Voice Mode is limited by safety policies such as anti-voice cloning. Additional safety guardrails also greatly limit its output capabilities by neutering the AI in the areas of bias, fairness, misinformation, social psychology, cybersecurity and more. While the mitigation of AI risks helps to reduce some undesirable aspects, they also increase others such as the inability to reply like a normal person would. Certain subjects and ideas are neutered like draconian censorship without recourse, preventing GTP-4o from replying to prompts with triggering replies.
Readers who want to test out GPT-4o can sign up for a free account today. Interested developers can learn how to create apps with GPT-4 from this book on Amazon. The lazy that simply want to enjoy the sun, snap vacation photos, and find directions to the local cantina by voice prompts can buy the Ray-Ban glasses with Meta AI on Amazon.
Source(s)
May 13, 2024
Hello GPT-4o
We’re announcing GPT-4o, our new flagship model that can reason across audio, vision, and text in real time.
All videos on this page are at 1x real time.
Guessing May 13th’s announcement.
GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction—it accepts as input any combination of text, audio, and image and generates any combination of text, audio, and image outputs. It can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time(opens in a new window) in a conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models.
Model capabilities
Two GPT-4os interacting and singing.
Interview prep.
Rock Paper Scissors.
Sarcasm.
Math with Sal and Imran Khan.
Two GPT-4os harmonizing.
Point and learn Spanish.
Meeting AI.
Real-time translation.
Lullaby.
Talking faster.
Happy Birthday.
Dog.
Dad jokes.
GPT-4o with Andy, from BeMyEyes in London.
Customer service proof of concept.
Prior to GPT-4o, you could use Voice Mode to talk to ChatGPT with latencies of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4) on average. To achieve this, Voice Mode is a pipeline of three separate models: one simple model transcribes audio to text, GPT-3.5 or GPT-4 takes in text and outputs text, and a third simple model converts that text back to audio. This process means that the main source of intelligence, GPT-4, loses a lot of information—it can’t directly observe tone, multiple speakers, or background noises, and it can’t output laughter, singing, or express emotion.
With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations.
Explorations of capabilities
Select sample:Visual Narratives - Robot Writer’s Block
Visual narratives - Sally the mailwoman
Poster creation for the movie 'Detective'
Character design - Geary the robot
Poetic typography with iterative editing
1Poetic typography with iterative editing
2Commemorative coin design for GPT-4o
Photo to caricature
Text to font
3D object synthesis
Brand placement - logo on coaster
Poetic typography
Multiline rendering - robot texting
Meeting notes with multiple speakers
Lecture summarization
Variable binding - cube stacking
Concrete poetry
A first person view of a robot typewriting the following journal entries:
1. yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
the text is large, legible and clear. the robot's hands type on the typewriter.
The robot wrote the second entry. The page is now taller. The page has moved up. There are two entries on the sheet:
yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
sound update just dropped, and it's wild. everything's got a vibe now, every sound's like a new secret. makes you think, what else am i missing?
The robot was unhappy with the writing so he is going to rip the sheet of paper. Here is his first person view as he rips it from top to bottom with his hands. The two halves are still legible and clear as he rips the sheet.
Model evaluations
As measured on traditional benchmarks, GPT-4o achieves GPT-4 Turbo-level performance on text, reasoning, and coding intelligence, while setting new high watermarks on multilingual, audio, and vision capabilities.
Improved Reasoning - GPT-4o sets a new high-score of 88.7% on 0-shot COT MMLU (general knowledge questions). All these evals were gathered with our new simple evals(opens in a new window) library. In addition, on the traditional 5-shot no-CoT MMLU, GPT-4o sets a new high-score of 87.2%. (Note: Llama3 400b(opens in a new window) is still training)
Audio ASR performance - GPT-4o dramatically improves speech recognition performance over Whisper-v3 across all languages, particularly for lower-resourced languages.
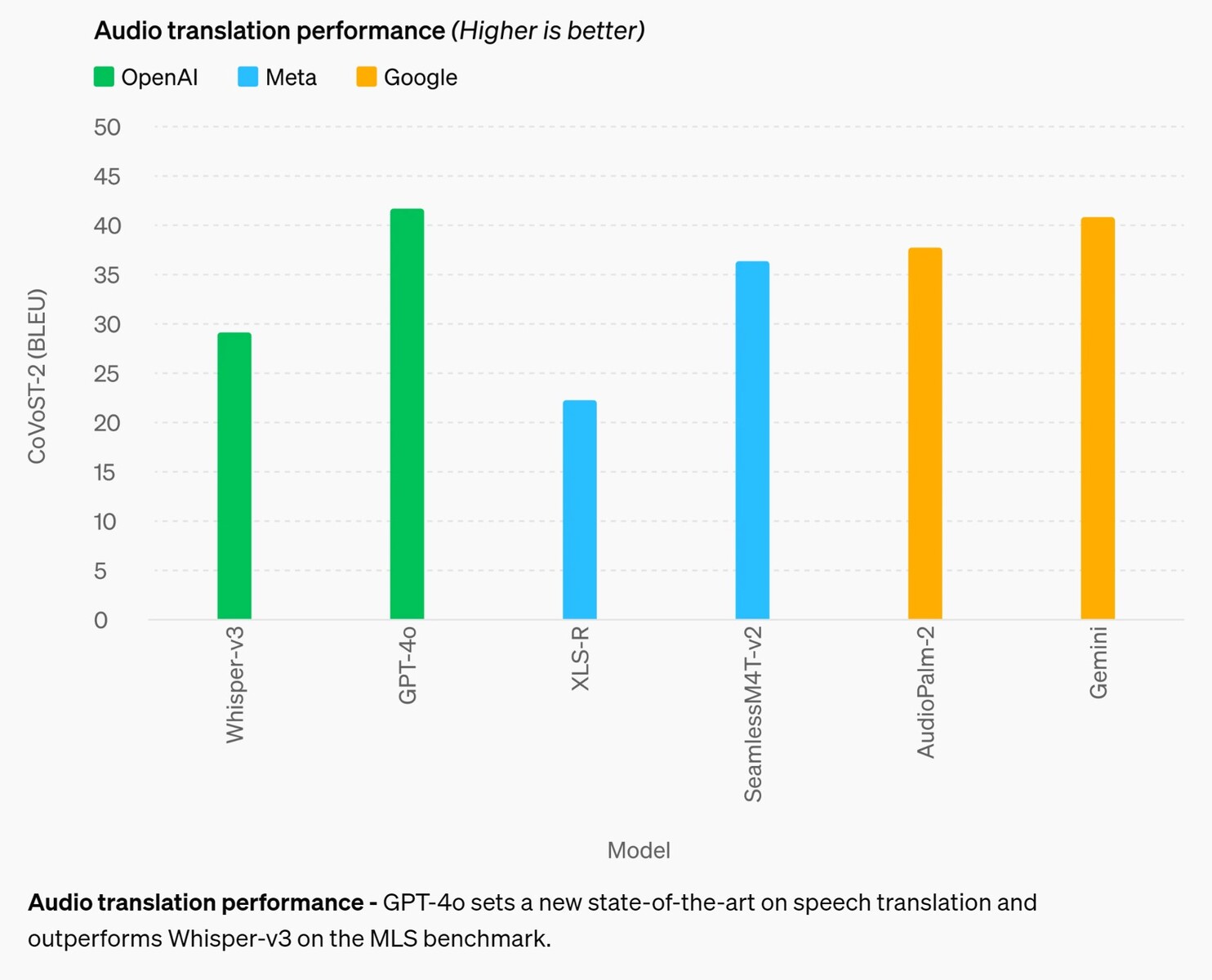
Audio translation performance - GPT-4o sets a new state-of-the-art on speech translation and outperforms Whisper-v3 on the MLS benchmark.
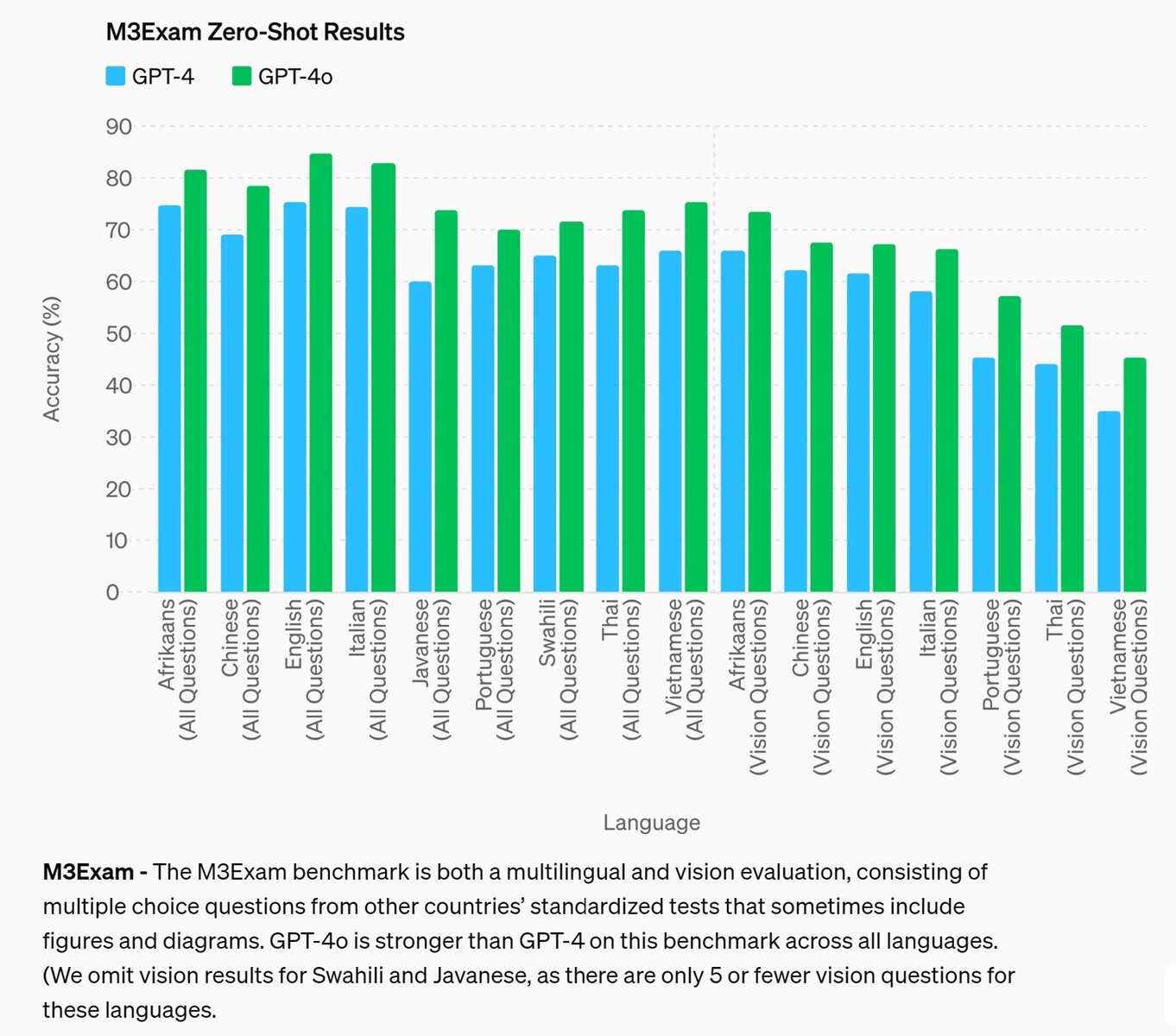
M3Exam - The M3Exam benchmark is both a multilingual and vision evaluation, consisting of multiple choice questions from other countries’ standardized tests that sometimes include figures and diagrams. GPT-4o is stronger than GPT-4 on this benchmark across all languages. (We omit vision results for Swahili and Javanese, as there are only 5 or fewer vision questions for these languages.
Vision understanding evals - GPT-4o achieves state-of-the-art performance on visual perception benchmarks.
Language tokenization
These 20 languages were chosen as representative of the new tokenizer's compression across different language families
Gujarati 4.4x fewer tokens (from 145 to 33) | હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. તમને મળીને સારું લાગ્યું! |
Telugu 3.5x fewer tokens (from 159 to 45) | నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. మిమ్మల్ని కలిసినందుకు సంతోషం! |
Tamil 3.3x fewer tokens (from 116 to 35) | வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். உங்களை சந்தித்ததில் மகிழ்ச்சி! |
Marathi 2.9x fewer tokens (from 96 to 33) | नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हाला भेटून आनंद झाला! |
Hindi 2.9x fewer tokens (from 90 to 31) | नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा! |
Urdu 2.5x fewer tokens (from 82 to 33) | ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا! |
Arabic 2.0x fewer tokens (from 53 to 26) | مرحبًا، اسمي جي بي تي-4o. أنا نوع جديد من نموذج اللغة، سررت بلقائك! |
Persian 1.9x fewer tokens (from 61 to 32) | سلام، اسم من جی پی تی-۴او است. من یک نوع جدیدی از مدل زبانی هستم، از ملاقات شما خوشبختم! |
Russian 1.7x fewer tokens (from 39 to 23) | Привет, меня зовут GPT-4o. Я — новая языковая модель, приятно познакомиться! |
Korean 1.7x fewer tokens (from 45 to 27) | 안녕하세요, 제 이름은 GPT-4o입니다. 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
Vietnamese 1.5x fewer tokens (from 46 to 30) | Xin chào, tên tôi là GPT-4o. Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn! |
Chinese 1.4x fewer tokens (from 34 to 24) | 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
Japanese 1.4x fewer tokens (from 37 to 26) | こんにちわ、私の名前はGPT−4oです。私は新しいタイプの言語モデルです、初めまして |
Turkish 1.3x fewer tokens (from 39 to 30) | Merhaba, benim adım GPT-4o. Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum! |
Italian 1.2x fewer tokens (from 34 to 28) | Ciao, mi chiamo GPT-4o. Sono un nuovo tipo di modello linguistico, è un piacere conoscerti! |
German 1.2x fewer tokens (from 34 to 29) | Hallo, mein Name is GPT-4o. Ich bin ein neues KI-Sprachmodell. Es ist schön, dich kennenzulernen. |
Spanish 1.1x fewer tokens (from 29 to 26) | Hola, me llamo GPT-4o. Soy un nuevo tipo de modelo de lenguaje, ¡es un placer conocerte! |
Portuguese 1.1x fewer tokens (from 30 to 27) | Olá, meu nome é GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
French 1.1x fewer tokens (from 31 to 28) | Bonjour, je m'appelle GPT-4o. Je suis un nouveau type de modèle de langage, c'est un plaisir de vous rencontrer! |
English 1.1x fewer tokens (from 27 to 24) | Hello, my name is GPT-4o. I'm a new type of language model, it's nice to meet you! |
Model safety and limitations
GPT-4o has safety built-in by design across modalities, through techniques such as filtering training data and refining the model’s behavior through post-training. We have also created new safety systems to provide guardrails on voice outputs.
We’ve evaluated GPT-4o according to our Preparedness Framework and in line with our voluntary commitments. Our evaluations of cybersecurity, CBRN, persuasion, and model autonomy show that GPT-4o does not score above Medium risk in any of these categories. This assessment involved running a suite of automated and human evaluations throughout the model training process. We tested both pre-safety-mitigation and post-safety-mitigation versions of the model, using custom fine-tuning and prompts, to better elicit model capabilities.
GPT-4o has also undergone extensive external red teaming with 70+ external experts in domains such as social psychology, bias and fairness, and misinformation to identify risks that are introduced or amplified by the newly added modalities. We used these learnings to build out our safety interventions in order to improve the safety of interacting with GPT-4o. We will continue to mitigate new risks as they’re discovered.
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities. For example, at launch, audio outputs will be limited to a selection of preset voices and will abide by our existing safety policies. We will share further details addressing the full range of GPT-4o’s modalities in the forthcoming system card.
Through our testing and iteration with the model, we have observed several limitations that exist across all of the model’s modalities, a few of which are illustrated below.
We would love feedback to help identify tasks where GPT-4 Turbo still outperforms GPT-4o, so we can continue to improve the model.
Model availability
GPT-4o is our latest step in pushing the boundaries of deep learning, this time in the direction of practical usability. We spent a lot of effort over the last two years working on efficiency improvements at every layer of the stack. As a first fruit of this research, we’re able to make a GPT-4 level model available much more broadly. GPT-4o’s capabilities will be rolled out iteratively (with extended red team access starting today).
GPT-4o’s text and image capabilities are starting to roll out today in ChatGPT. We are making GPT-4o available in the free tier, and to Plus users with up to 5x higher message limits. We'll roll out a new version of Voice Mode with GPT-4o in alpha within ChatGPT Plus in the coming weeks.
Developers can also now access GPT-4o in the API as a text and vision model. GPT-4o is 2x faster, half the price, and has 5x higher rate limits compared to GPT-4 Turbo. We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
