OpenAI unveils GPT-4o mini with a price 25x lower than GPT-4o, allowing more businesses and users to access quality AI

OpenAI has unveiled GPT-4o mini with a price more than 25x lower than its top-ranked GPT-4o, opening access to quality AI for more businesses and users. GPT-4o mini has been independently ranked among the top 10 most capable AI models available today. GPT-4o mini performs well across a range of AI benchmarks despite being a small LLM model.
A Large Language Model (LLM) is created after training on millions of documents and forms the basis for an AI chatbot like ChatGPT. The model then holds mathematical vectors that associate the probability of words, pictures, and more occurring with each other. For example, the likelihood of ‘ice’ appearing next to ‘cream’ is far greater than it appearing next to ‘stone’. However, a big LLM uses lots of computing power and energy to answer user prompts, which equals a high cost for users. Trimming LLMs can make them smaller, cheaper, and more eco-friendly with the tradeoff of less accurate answers.
Readers who don’t know how to use AI to do business tasks better or to make more money can read this book on Amazon.
In a direct comparison with GPT-4o, OpenAI’s best LLM released in 2024, GPT-4o mini consistently outputs less accurate answers. When compared to 2022’s GPT-3.5 Turbo, GPT-4o mini consistently performs better. On a variety of college-level AI benchmarks (DROP, HumanEval, MATH, MathVista, MGSM, MMLU, and MMMU), the model answers questions accurately roughly 60 to 80% of the time. It is only on the PhD graduate level test (GPQA) that its accuracy drops to roughly 40%, or just slightly better than a non-expert searching for an answer online.
Importantly, while GPT-4o is priced at $5/1M input tokens and $15/1M output tokens, GPT-4o mini is priced at $0.15/1M input and $0.60/1M output (1000 tokens is approximately 750 words). This is cheaper than approximately eighty common LLMs in use today, with the exception of mistral-embed.
GPT-4o mini has a 128K token input context window, which is the amount of text that can be analyzed at once, so the analysis of large volumes of business and legal documents is limited. The output window is limited to 16K tokens. The model also has a knowledge cutoff of October 2023, so news, events, and discoveries that occur after this date are unknown to the AI and cannot be used in answering prompts.
Readers who are still waiting for AI humanoid robots to come clean and cook for them, like the 1X Neo prototype, will have to settle for non-AI robots (like this vacuum cleaner on Amazon) in the meantime.

Source(s)
July 18, 2024
GPT-4o mini: advancing cost-efficient intelligence
Introducing our most cost-efficient small model
OpenAI is committed to making intelligence as broadly accessible as possible. Today, we're announcing GPT-4o mini, our most cost-efficient small model. We expect GPT-4o mini will significantly expand the range of applications built with AI by making intelligence much more affordable. GPT-4o mini scores 82% on MMLU and currently outperforms GPT-41 on chat preferences in LMSYS leaderboard(opens in a new window). It is priced at 15 cents per million input tokens and 60 cents per million output tokens, an order of magnitude more affordable than previous frontier models and more than 60% cheaper than GPT-3.5 Turbo.
GPT-4o mini enables a broad range of tasks with its low cost and latency, such as applications that chain or parallelize multiple model calls (e.g., calling multiple APIs), pass a large volume of context to the model (e.g., full code base or conversation history), or interact with customers through fast, real-time text responses (e.g., customer support chatbots).
Today, GPT-4o mini supports text and vision in the API, with support for text, image, video and audio inputs and outputs coming in the future. The model has a context window of 128K tokens, supports up to 16K output tokens per request, and has knowledge up to October 2023. Thanks to the improved tokenizer shared with GPT-4o, handling non-English text is now even more cost effective.
A small model with superior textual intelligence and multimodal reasoning
GPT-4o mini surpasses GPT-3.5 Turbo and other small models on academic benchmarks across both textual intelligence and multimodal reasoning, and supports the same range of languages as GPT-4o. It also demonstrates strong performance in function calling, which can enable developers to build applications that fetch data or take actions with external systems, and improved long-context performance compared to GPT-3.5 Turbo.
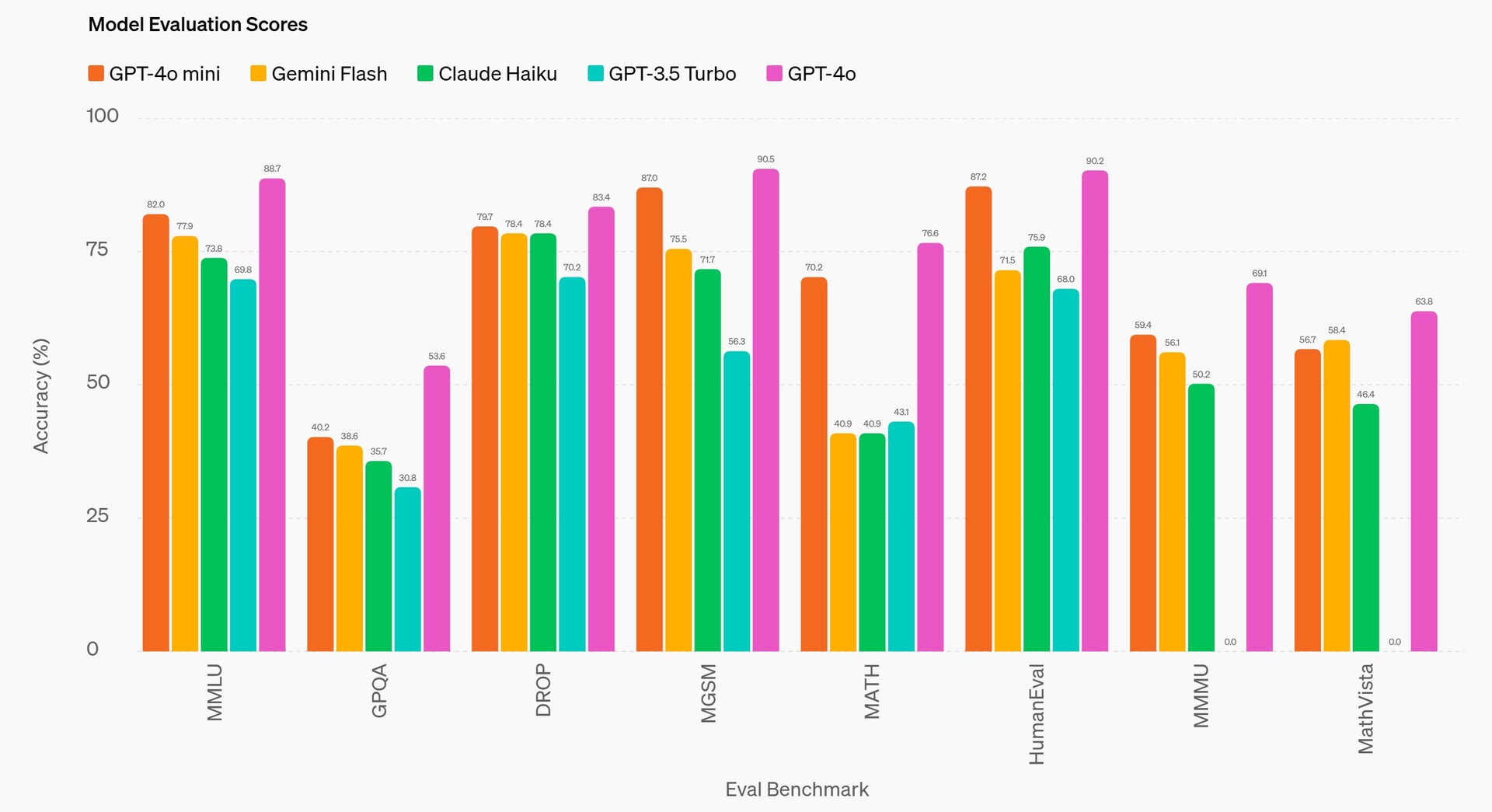
GPT-4o mini has been evaluated across several key benchmarks2.
Reasoning tasks: GPT-4o mini is better than other small models at reasoning tasks involving both text and vision, scoring 82.0% on MMLU, a textual intelligence and reasoning benchmark, as compared to 77.9% for Gemini Flash and 73.8% for Claude Haiku.
Math and coding proficiency: GPT-4o mini excels in mathematical reasoning and coding tasks, outperforming previous small models on the market. On MGSM, measuring math reasoning, GPT-4o mini scored 87.0%, compared to 75.5% for Gemini Flash and 71.7% for Claude Haiku. GPT-4o mini scored 87.2% on HumanEval, which measures coding performance, compared to 71.5% for Gemini Flash and 75.9% for Claude Haiku.
Multimodal reasoning: GPT-4o mini also shows strong performance on MMMU, a multimodal reasoning eval, scoring 59.4% compared to 56.1% for Gemini Flash and 50.2% for Claude Haiku.
As part of our model development process, we worked with a handful of trusted partners to better understand the use cases and limitations of GPT-4o mini. We partnered with companies like Ramp(opens in a new window) and Superhuman(opens in a new window) who found GPT-4o mini to perform significantly better than GPT-3.5 Turbo for tasks such as extracting structured data from receipt files or generating high quality email responses when provided with thread history.
Built-in safety measures
Safety is built into our models from the beginning, and reinforced at every step of our development process. In pre-training, we filter out(opens in a new window) information that we do not want our models to learn from or output, such as hate speech, adult content, sites that primarily aggregate personal information, and spam. In post-training, we align the model’s behavior to our policies using techniques such as reinforcement learning with human feedback (RLHF) to improve the accuracy and reliability of the models’ responses.
GPT-4o mini has the same safety mitigations built-in as GPT-4o, which we carefully assessed using both automated and human evaluations according to our Preparedness Framework and in line with our voluntary commitments. More than 70 external experts in fields like social psychology and misinformation tested GPT-4o to identify potential risks, which we have addressed and plan to share the details of in the forthcoming GPT-4o system card and Preparedness scorecard. Insights from these expert evaluations have helped improve the safety of both GPT-4o and GPT-4o mini.
Building on these learnings, our teams also worked to improve the safety of GPT-4o mini using new techniques informed by our research. GPT-4o mini in the API is the first model to apply our instruction hierarchy(opens in a new window) method, which helps to improve the model’s ability to resist jailbreaks, prompt injections, and system prompt extractions. This makes the model’s responses more reliable and helps make it safer to use in applications at scale.
We’ll continue to monitor how GPT-4o mini is being used and improve the model’s safety as we identify new risks.
Availability and pricing
GPT-4o mini is now available as a text and vision model in the Assistants API, Chat Completions API, and Batch API. Developers pay 15 cents per 1M input tokens and 60 cents per 1M output tokens (roughly the equivalent of 2500 pages in a standard book). We plan to roll out fine-tuning for GPT-4o mini in the coming days.
In ChatGPT, Free, Plus and Team users will be able to access GPT-4o mini starting today, in place of GPT-3.5. Enterprise users will also have access starting next week, in line with our mission to make the benefits of AI accessible to all.
What’s Next
Over the past few years, we’ve witnessed remarkable advancements in AI intelligence paired with substantial reductions in cost. For example, the cost per token of GPT-4o mini has dropped by 99% since text-davinci-003, a less capable model introduced in 2022. We’re committed to continuing this trajectory of driving down costs while enhancing model capabilities.
We envision a future where models become seamlessly integrated in every app and on every website. GPT-4o mini is paving the way for developers to build and scale powerful AI applications more efficiently and affordably. The future of AI is becoming more accessible, reliable, and embedded in our daily digital experiences, and we’re excited to continue to lead the way.
Author
OpenAI
Acknowledgments
Leads: Jacob Menick, Kevin Lu, Shengjia Zhao, Eric Wallace, Hongyu Ren, Haitang Hu, Nick Stathas, Felipe Petroski Such
Program Lead: Mianna Chen
Contributions noted in openai.com/gpt-4o-contributions/
Footnotes
1
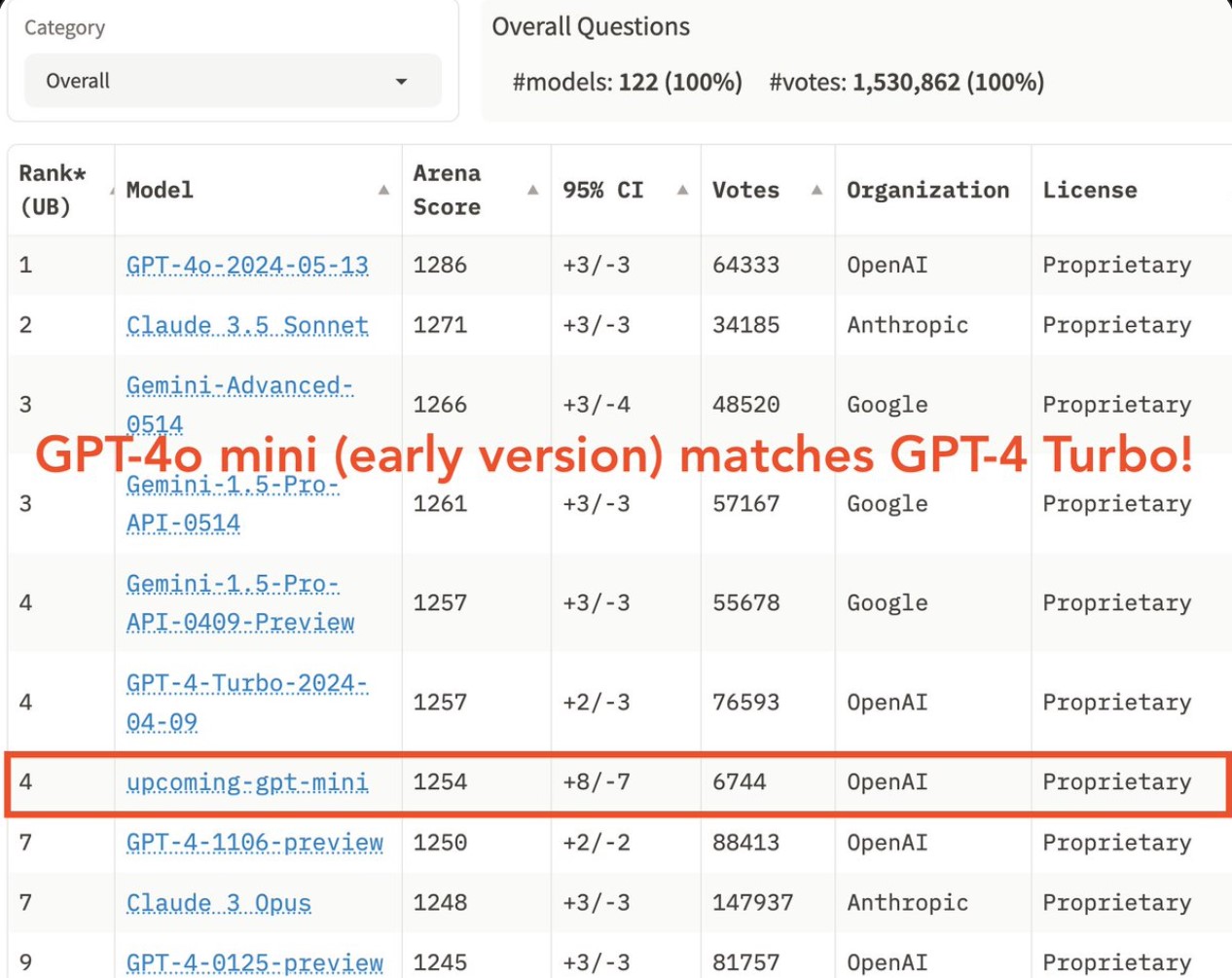
As of July 18th, 2024, an earlier version of GPT-4o mini outperforms GPT-4T 01-25.
2
Eval numbers for GPT-4o mini are computed using our simple-evals(opens in a new window) repo with the API assistant system message prompt. For competitor models, we take the maximum number over their reported number (if available), the HELM(opens in a new window) leaderboard, and our own reproduction via simple-evals.
