Leaked internal comms reveal Nvidia scraping lifetime worth of YouTube videos daily to train video AI model, Jensen happy with the progress

Nvidia is training its Omniverse, self-driving cars, and "digital human" cars based on data scraped from "80 years-worth of videos per day" from YouTube and other sources, an investigation by 404 Media revealed.
Leaked internal communications obtained by 404 Media indicate Nvidia is using this data to train its AI video world model dubbed Cosmos (not to be confused with the company's existing Cosmos Deep Learning service). Cosmos is internally slated to be a model that would power other Nvidia lines including GeForce, GPU architecture, DGX, Deep Learning frameworks, Omniverse, Avatar, Project GR00T, and autonomous vehicles.
Nvidia execs dubbed Cosmos as a state-of-the-art foundation model "that encapsulates simulation of light transport, physics, and intelligence in one place to unlock various downstream applications critical to Nvidia.”
404 Media accessed internal employee Slack messages that revealed how staff used the command-line yt-dlp program to download YouTube videos using 20 to 30 AWS virtual machines that refresh IP addresses to avoid getting blocked by YouTube. The video sharing site was the main source for scraping videos, with employees also mulling over other sources like Netflix and Discovery Channel.
Slack communications show employees discussing the legal ramifications of scraping copyrighted content to train AI only to be dismissed by project managers as an executive decision, and that is something they needn't worry about.
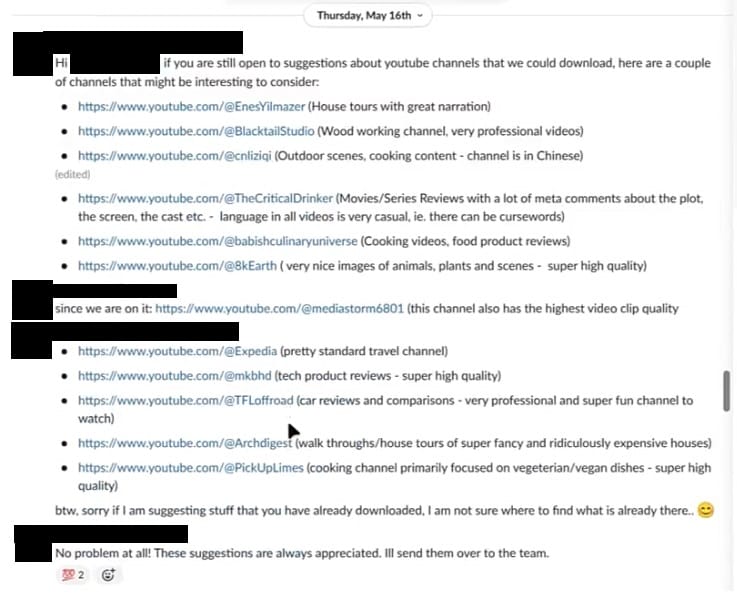
Popular YouTube channels that Nvidia employees have shortlisted include MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth, and The CriticalDrinker among others.
When contacted by 404 Media, both YouTube and Netflix said that scraping content on their platforms to train AI models are a clear violation of their terms of service.
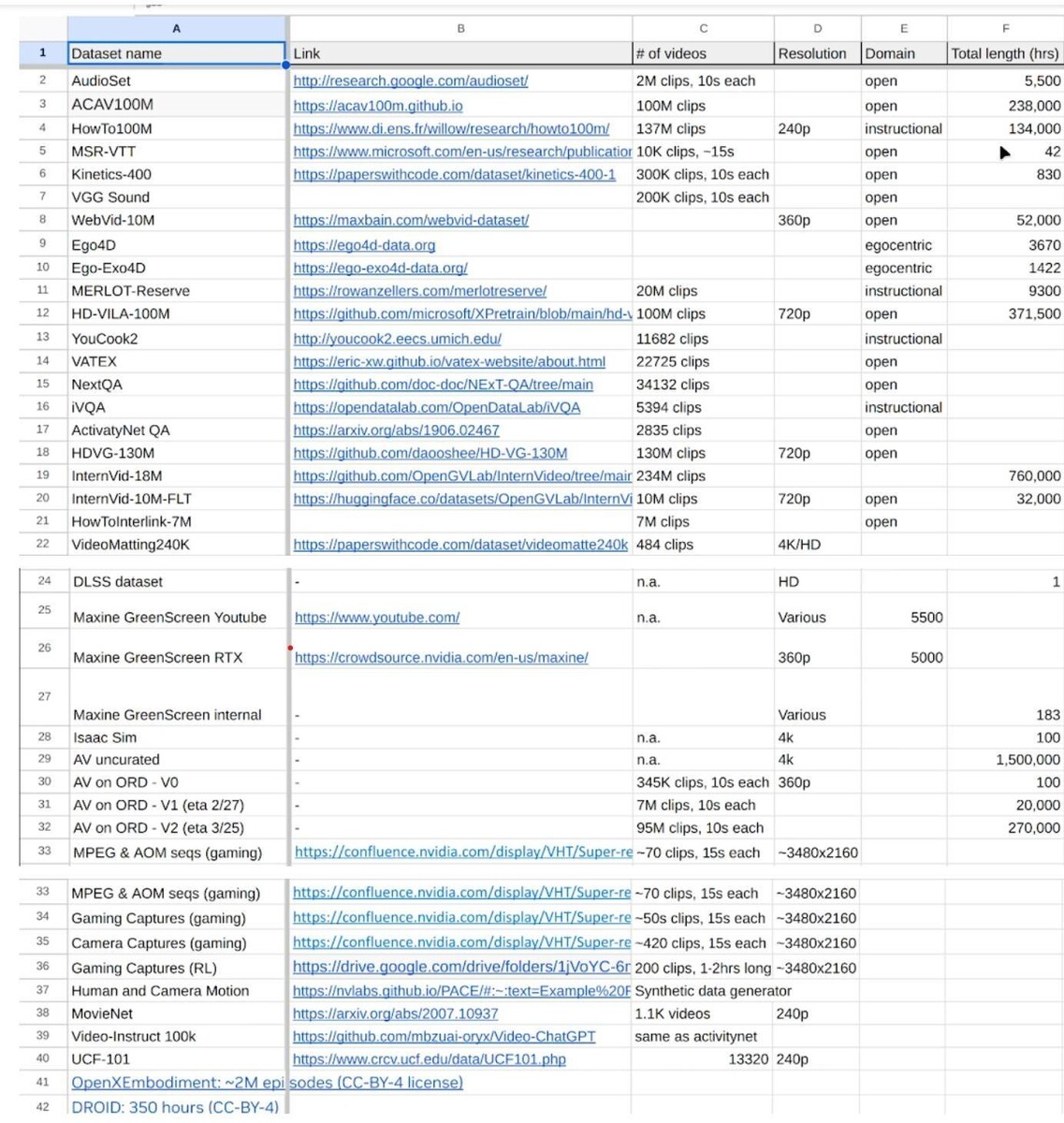
The use of copyrighted data to train AI models is still a legal grey area. Public datasets such as InternVid-10M, HD-VG-130M, and others based on millions on YouTube videos exist, but they are only meant for academic research and not for commercial purposes. Although Nvidia has academic researchers, the output will eventually make its way to a commercial product.
There have been few legislations to this effect that mandate transparency standards and requirement of companies working on foundational AI models to work with the FTC and the Copyright Office. But companies do not necessarily disclose their source datasets, which makes auditing a lot more difficult.
As major AI companies continue to lay their hands on all available public data to train more effective models, legislative changes are a dire need of the hour to ensure consumer safety and protect creator IP.
Last year, The New York Times sued OpenAI and Microsoft for unauthorized use of the publication's copyrighted articles to train AI models. In May, visual artists filed a lawsuit against Stability AI, Midjourney, DeviantArt, and Runway AI for using copies of their work to train AI models without permission.
YouTube is turning out to be a data goldmine for AI companies. Recently, Wired reported that heavyweights including Apple, Nvidia, Anthropic, and Salesforce scraped subtitles from 173,536 YouTube videos from more than 48,000 channels to train their AI.
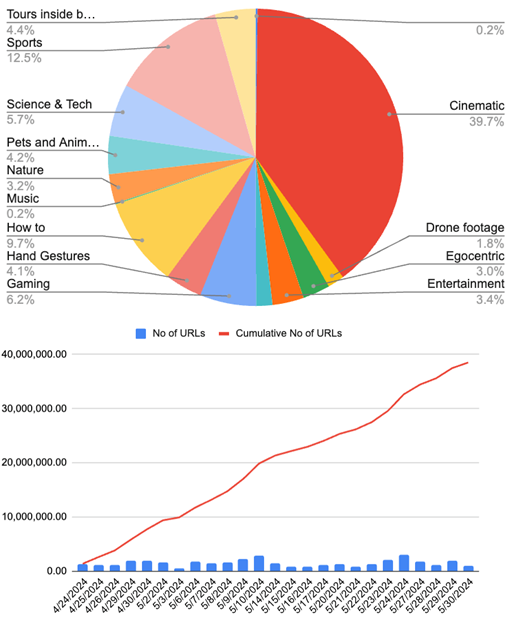
Up till late May, Nvidia staff announced internally they had compiled 38.5 million video URLs, with the majority of them being cinematic content. The engineers also added datasets such as Ego-Exo4D, Ego4D, HOI4D, and game data from GeForce Now.
While Ego-Exo4D and Ego4D can be licensed for both academic and commercial use, HOI4D is distributed under a CC BY-NC license that specifically prohibits commercial use.
The team is currently training a 1B model each with 16 nodes, with plans to scale it up 10B.
Nvidia told 404 Media via email, "our models and our research efforts are in full compliance with the letter and the spirit of copyright law.”
Meanwhile, Nvidia CEO Jensen Huang seems to be happy with the progress his staff is making.
He reportedly exclaimed, “Great update. Many companies have to build video FM [foundational models]. We can offer a fully accelerated pipeline.”
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Source(s)
404 Media (requires signup)
