Interview | "Our big Middle cores are better than their army of little cores" AMD's Ben Conrad chats about some of the design decisions behind Ryzen AI APUs and what makes Strix Halo tick

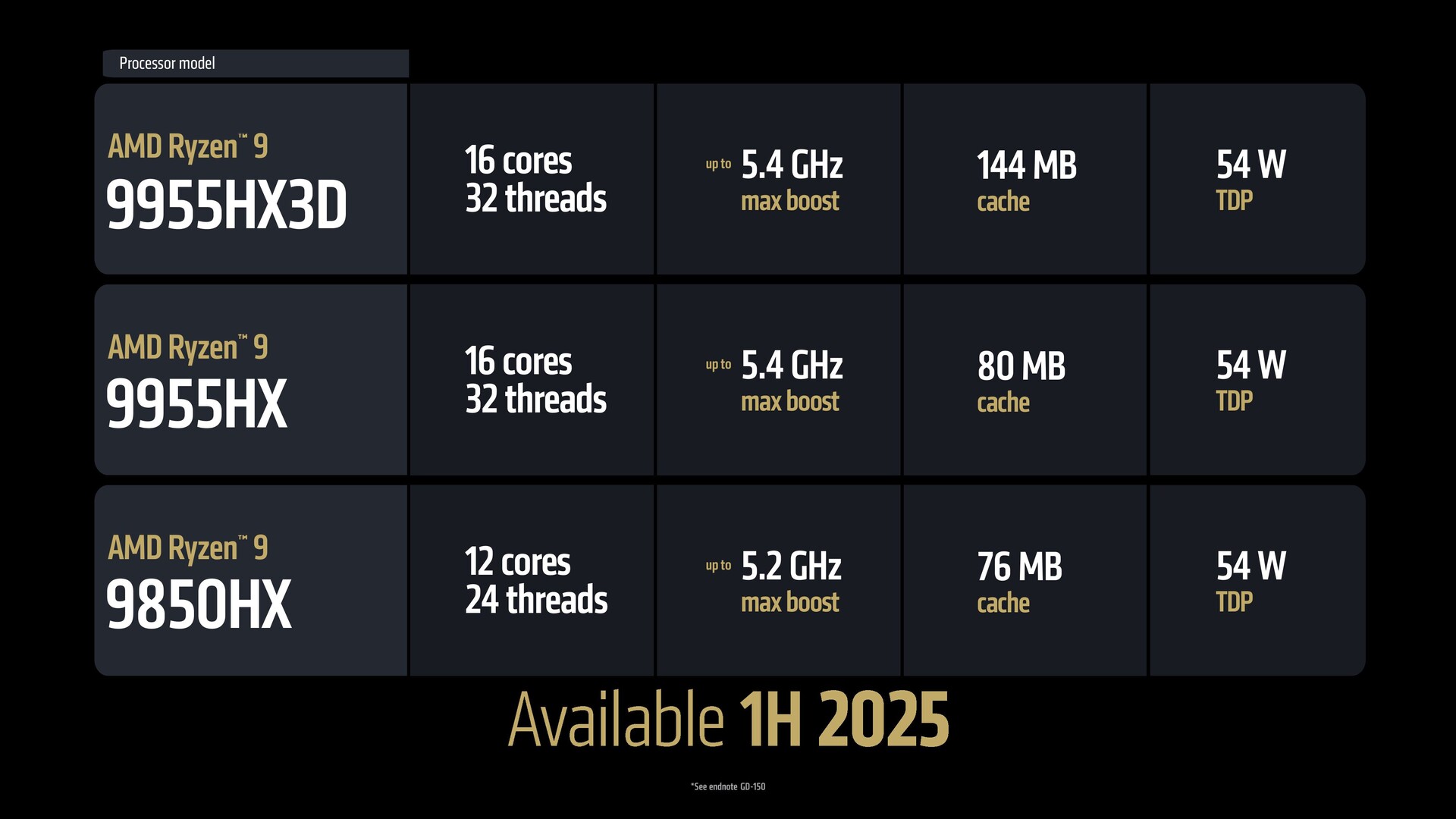
AMD had a busy CES 2025 with a slew of new hardware announcements. These include the Ryzen 9 9950X3D desktop CPU, Ryzen 9 9955HX3D and other Fire Range APUs, a sneak peek at RDNA 4, new Ryzen AI 300 and 200 Series APUs, and the flagship Ryzen AI Max Strix Halo.
On the sidelines of the event, Notebookcheck's Vaidyanathan Subramaniam (VS) caught up with AMD's Ben Conrad, Director of Product Management for Premium Mobile Client, to talk about the new Ryzen APU launches and what they mean for AMD vis-ȧ-vis the competition, and the direction the mobile market is likely to head in the coming days.
TL;DR: AMD exudes optimism with Strix Point and Strix Halo
Here's a quick summary of what we've gleaned from our interaction with Ben. The full interview follows below:
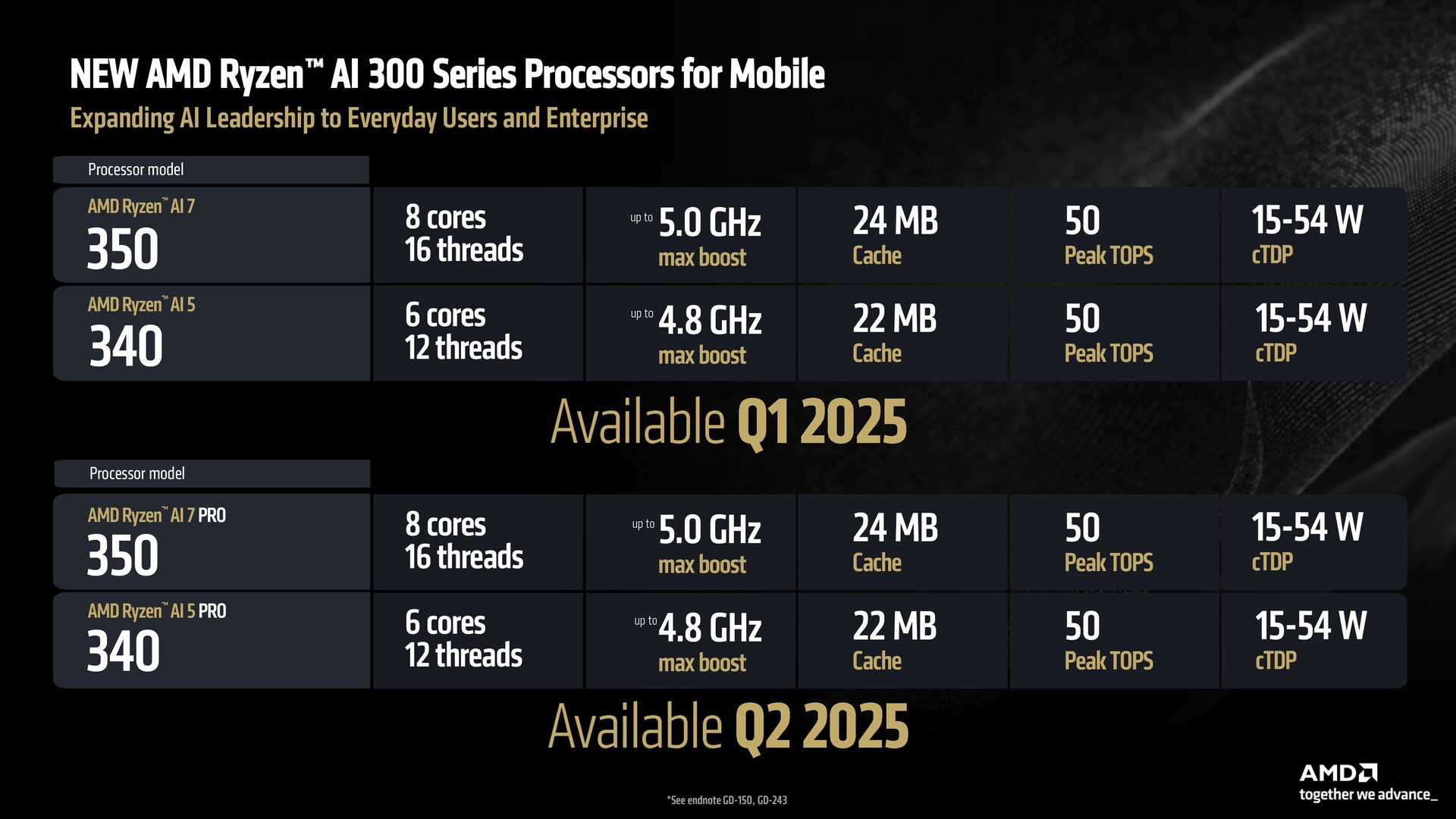
- Ryzen AI 300 Series offers a complete portfolio for users of all requirements.
- All Ryzen AI 300 Series and the Ryzen AI 200 Series are package-compatible with previous Strix Point launches.
- No plans for bringing Ryzen AI 300 and 200 Series to Chromebooks.
- AMD's "big Middle" implementation with Zen 5 and Zen 5c cores is a better bet than the competition's P-core/E-core approach with little to no scheduling penalties.
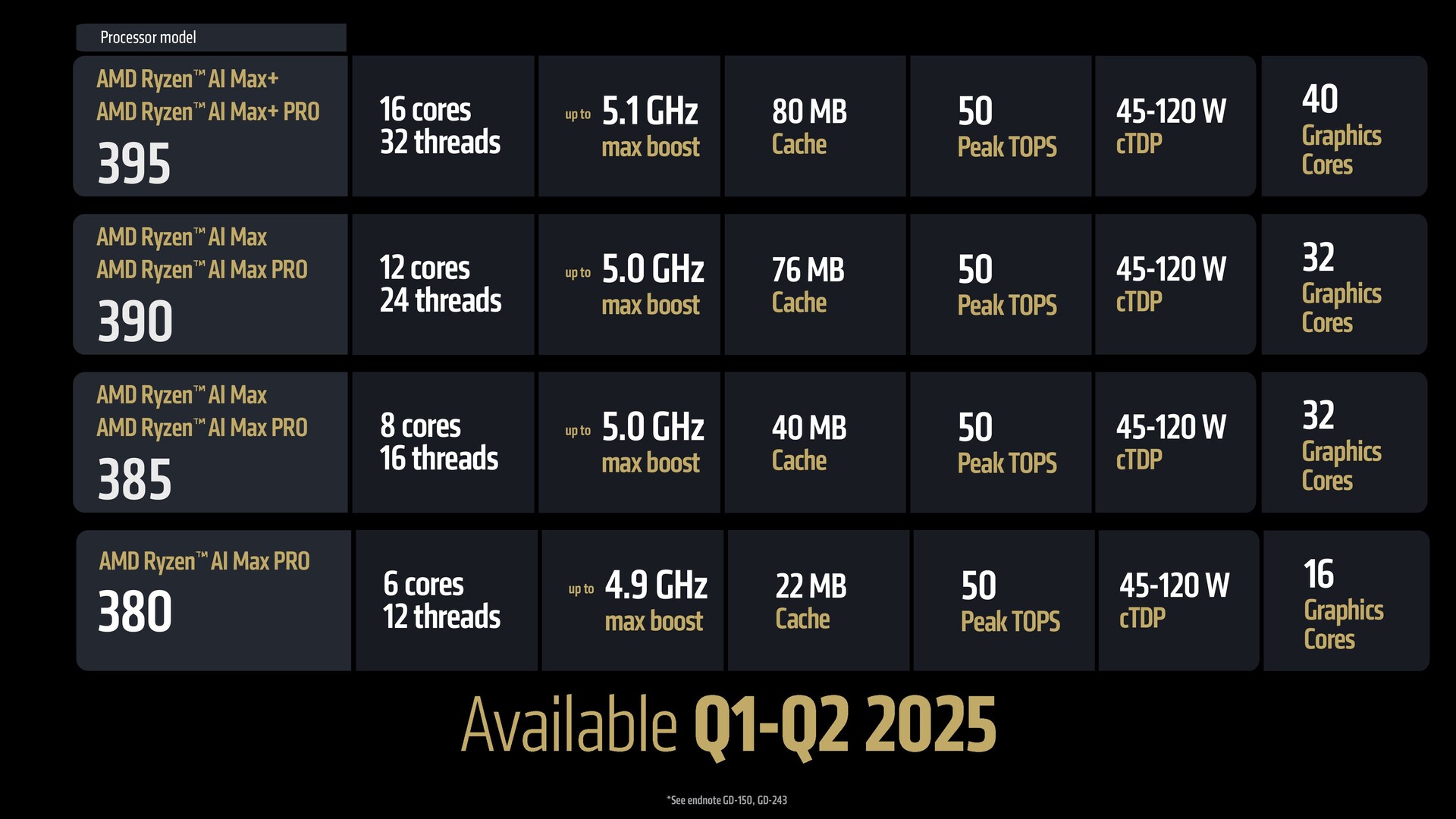
- Strix Halo Ryzen AI Max uses the same "classic" Zen 5 cores as desktop Ryzen 9000 and Fire Range HX 3D parts.
- Strix Halo is derived from the desktop and features AVX-512, but sports different interconnects optimized for power.
- Strix Halo's RDNA 3.5 offers equivalent memory bandwidth to an RTX 4070 together with 32 MB Infinity Cache. Conscious decision to not opt for on-package memory.
- Ryzen AI APUs use a better SmartShift algorithm optimized for power budgets.
- Strix Halo does not support dGPUs and features only 12 PCIe Gen 4 lanes from the CPU. Will be coming to mini PCs as well.
- Ryzen AI Max doubles memory speeds to LPDDR5-8000 and offers similar bandwidth as the RTX 4070.
- No Dragon Range Refresh planned at the moment, but future Fire Range Refresh not ruled out.
- RDNA 4 will be focused only on the desktop, but future mobile dGPUs and APUs are a definite possibility.
- There are plans to bring NPU capabilities to lower price points over time.
The apparent Ryzen AI advantage
VS: Thank you for your time, Ben. Let's start off with how AMD sees itself with the new announcements, their market positioning, and thoughts on the competition, particularly in the laptop segment.
Ben: The overall picture is one of great potential. We've got the Ryzen AI 300, which we are expanding to the Ryzen AI 7 and Ryzen AI 5 SKUs. We also have the Ryzen 9 9955HX3D for high-end gaming and workstation (laptops). Then we've got the disruptive Ryzen AI Max for thin and light gaming and thin and light workstations — kind of a best of everything system.
In comparison with our competitors, the Ryzen AI 300 Series is a Swiss army knife. It has dGPU attached, so it supports thin and light gaming. If you value the ability to replace or add memory to your system, it supports DDR5 expansion that the competition lacks. Finally, in the gaming systems, it also offers Copilot+.
All of these things make it unique. Our competitors are having to have multiple products come out to cover that same area whereas we are able to do all of that with the 300 Series. And then we go do cool, crazy stuff like the Ryzen AI Max even on top of that.
One other input for our OEM customers in laptops is that we have a package compatibility story. All of the 300 Series, including Strix Point we launched in the summer and Kraken Point that we're launching now, are package compatible and can be offered in the same system. All of the Ryzen 200 Series that are Hawk Point Zen 4-based are also package compatible.



So, we give one system at multiple price points — Copilot+ and AI with huge graphics capabilities, all the way down to the N minus one product that is still great and still competes quite well in the market.
If the buyer values the chassis features of that platform and they want it at a (lower) price point, we've got the 200 Series and if they want the futureproofing of AI and all the capabilities of the 300 Series, we have that as well. There's flexibility.
VS: Are you offering any distilled down products for Chromebooks based on these like what we've seen with the Ryzen 7020C series?
Ben: We do not have plans for the 300 Series in Chromebooks.
VS: What about the 200 Series?
Ben: I don't think we have for 200 either (for Chromebooks).
AMD's big Middle approach with Zen 5 and Zen 5c
VS: Do the high-end SKUs come with a mix of Zen 5 and Zen 5c or is it all Zen 5? What would be the fundamental difference between these cores?
Ben: That's a great question. Many of the SKUs in the 300 Series offer a mix of Zen 5 "classic" and Zen 5 "compact". Our competitors are using the "army of little cores approach" in a lot of their systems to get a multi-threading benchmark.
So, you've got lots of little tiny cores that may not be ISA compatible you know, there might be some translation when you need to move the process between the cores. Let's call this what ARM refers to as big.LITTLE. I would call our approach "big Middle". The compact cores that we have use the same instruction set and much higher performance than the super, super low cores on the others.
And so, in a platform where you're power-limited, you have a maximum boost frequency for one thread. You can't run every single core on almost every laptop at that maximum frequency at the same time. So, these compact cores usually have a little bit lower maximum frequency. But there's almost no penalty because if you're in a one-thread scenario, you can boost one of the classic cores.
These compact cores are in a safe area, so we can do interesting stuff with other IP. They also offer a different performance curve in cases where we want the process to be on a lower power core, but that's essentially the story there.
It's not a huge translation to and in between, and the key thing about these (compact cores) is that they perform almost like a classic core at lower frequencies and then, you know, they don't scale to the higher frequencies, which doesn't really impact the system because you've got the one-thread scaling in the classic cores.

Intel Thread Director vis-ȧ-vis AMD's idea
VS: So, you're saying the OS essentially does not see them as a different ISA. That means in theory, at least, a lot of the potential scheduling issues should be alleviated?
Ben: The OS does see them as hetero cores, but the penalties for not being perfect in scheduling are much lower.
VS: Okay. Regarding the scheduling aspect or how you prioritize the thread on which core to go, can the user have a frontend to control it? Just to give you some context, your competitor has something called the Thread Director. What happens here is that the logic is decided by the CPU. But many times, we found that if it parks a certain game or a benchmark on the E-cores, the scores go down unless you're able to manually override this with third-party tools.
Does AMD have any plans for giving control to pro users who would like to play around with the threads, whether in the BIOS or with Ryzen Master? I believe a basal thread control will always be there with the processor. But if it's a program like say Discord, and I just want to push it to the Zen 5c core, would that be possible?
Ben: Our competitor needs Thread Director because of the huge difference between the cores. So, if you don't have that operating well, you have a very bad experience. There are actually games out there that detect how many big cores there are and only spawn threads for those cores because of the penalty of getting around all the other cores. There are several games out there that you see actually spawning different number of threads based on the big core count they assess from the system.


The penalty again on AMD is much lower of that happening. I believe you do have a couple of capabilities to set thread affinity to help where it is. I'm not really up to date on all of the software features we have to do the customization. We probably have to revert if we could try to find an internal software product manager that could give you the best answer.
For context, Intel took a potshot at AMD's lack of a similar mechanism while explaining what Thread Director is all about.
VS: In the portfolio that has been announced now, do we have Zen 5c in any of the higher-end SKUs? The Ryzen AI Max, I believe, is all Zen 5?
Ben: Right, the Max is all Zen 5. It also has AVX-512, so that's a server-level feature that's in the Ryzen AI Max with all classic cores. That's the maximum; we just threw everything we had in that, so maximum performance, you know, the same 16 classic cores is what's available in the 9950X3D and the Fire Range 9955HX3D. That same capability is now scaled into form factors that those platforms can hit.
VS: Is Fire Range essentially just a desktop part binned into a laptop chip or are there other mobile-specific enhancements? I believe the 9955HX3D is at 140 W while the 9950X3D goes up to 170 W?
Ben: Yeah, it is the same silicon, and so you're right. It's the binning, there's software, there's tuning, there's a different package — those are the differences that that differentiate that product, but it's using that same base that's powering the 9950 on the desktop.
Design decisions behind Strix Halo Ryzen AI Max
VS: The Fire Range laptops won't be getting the Copilot+ branding, I believe, because there's no NPU being advertised on it? On the desktop side, if I remember correctly, Dr. Lisa Su was telling during the keynote that we have AVX-512, which should accelerate AI workloads, but there's no dedicated NPU as such on the desktop.
Ben: Neither the desktops nor Fire Range have dedicated NPUs. We absolutely believe that the NPU is in the future. I would expect trends at AMD and others in the industry would be bringing NPUs to these capabilities. But as of today, one characteristic in desktop and Fire Range is they have basically a 100% dGPU attach. So, you've got a huge amount of AI in the dGPU.
We first focus our NPU on UMA platforms. Or you know, platforms that that have a mix of power-constrained laptops. So that was the reason, and we have a huge breadth of NPUs across that, I think the best of any of any vendor.
VS: Which reminds me, speaking of UMA, do you think 256 GB/s should be enough memory bandwidth compared to, say Apple silicon? Is that bandwidth enough to really kind of push the data back and forth between IPs? And as an addendum, why is there no on-package memory for these?
Ben: So, the Ryzen AI Max uses literally double the LPDDR5 chips from the Ryzen 300 series or our competitors with a 128-bit bus. So that's big chips and that package would get gigantic. What we've heard from our customers is they like the flexibility of being able to buy memory and make their own decisions, and not us saying you have two options, you have this or that. So, that was a design decision not to include the memory on the package.
As far as the bandwidth, since we've doubled the width of the bus, at LPDDR5-8000 speeds, it's 256 gigs a second. And that is identical to the RTX 4070. In the place where we're trying to complete, we're at exactly the same bandwidth, so absolutely yes. If we had just put in a lot more graphics on the APU and not doubled the memory bandwidth, it would be extremely constrained.
So, you know, our architects look at not just one IP and make the number here higher. You have to look at the whole system, make sure you have the bandwidth and the power. We do have the 32 MB of Infinity Cache, kind of like a Level 4 cache on the chip. That's very similar to the Infinity Cache in Radeon graphics.
VS: This Infinity Cache is between the Radeon 8060S and the CCD?
Ben: That cache is between the rest of the chip and the memory interface. So, it's basically a last level cache similar to the Infinity Cache mechanism on our dGPUs, where it is between the GPU and the GDDR6 memory.
VS: Do you think Strix Halo can go in other form factors as well, like a mini PC?
Ben: Absolutely. We have a couple of small form factor desktops here (at CES). I am surprised by how many people and OEMs are excited about that small form factor.

VS: What kind of an interconnect is there between the CPU and the RDNA 3.5 GPU in the Ryzen AI Max? Do we have something on the lines of Infinity fabric and SmartShift?
Ben: The interconnect, we internally we call it DDR SSP. I have to figure out if that internal branding is different from what is used in the desktop chip, because we optimize that interconnect for power. When you hold up the Strix Halo die, you find that the CCDs are really close to the I/O die. And because of this we were able to save multiple Watts of power, which is the whole point of building Strix Halo as being really low power for high performance. So, it is a different interconnect, and it is not the identical CCD silicon as our desktop chips.
With SmartShift, you've got an APU and you've got a dGPU as separate chips, sloshing power between the two. Sensing that the dGPU is really getting maxed out, it says let's allocate this power to that. APUs have used SmartShift — our SmartShift technology is software based, and it's at the level of the firmware between these two chips.
Our APUs do effectively smart-shift, sharing power amongst the IPs at the hardware level because they are one package. Our APUs have always had, you know, something even better, even faster thinking, making that decision many more times a second on where the power should go.
So, yeah, effectively we haven't branded that (as SmartShift) in Ryzen AI Max but just inherent to the hardware of an APU, that's already happened.
VS: And this percolates down to all APUs in the stack?
Ben: Absolutely. Every single APU is allocating power to what is needed. If there's demand on both the dGPU and the cores, it looks at what has more demand and allocates there.
VS: On that aspect, can an OEM use the Ryzen AI Max and still offer a dGPU, say a Radeon dGPU?
Ben: The Ryzen AI Max does not support dGPU attached. Since we already have a dGPU class APU there's really no reason. You can't, you know, CrossFire them, so there's no point turning them on at the same time. Honestly, why would an OEM buy this solution and then try to bolt on a dGPU as now you are in a kind of the same form as an existing gaming form factor.
VS: In that case, how would you best utilize the PCIe lanes from the CPU? I believe a lot of lanes would be free as most of the (slim) designs hardly have one or two SSDs and OEMs tend to not offer scope for storage expansion in these chassis anyways, so you aren't utilizing the full PCIe bandwidth.
Ben: There's PCIe Gen 4 on these chips. Ryzen AI Max offers 12 lanes of PCIe Gen 4, and our typical APUs that have a dGPU attached have 16 to 20 lanes. So, the reason we cut that down is because you're usually using about eight lanes for the dGPU. Since we don't have a dGPU attached, you know, 20-8 gets to 12. We do want to be able to support dual SSDs and a couple of other I/Os, and some of our workstation customers I think are going to take advantage of that.
VS: So, one possibility would be that can you route USB4 to that instead of going to the chipset?
Ben: I'd have to check in on that. Usually in this small form factor, you know, there's no PCIe bridge chip or anything. You just want to use the APU to get that sizing.
Product nomenclature and future prospects
VS: Are there any new Dragon Range Refresh chips also coming out?
Ben: I think that is unlikely. I don't think we are announcing anything in the Dragon Range family at this point.
VS: Would that mean that you'll still continue to sell the chips that you've been selling last year?
Ben: Certainly. Even if an APU isn't in our current roadmap, if OEMs are still building systems with the previous designs, absolutely. There's a long tale of selling existing products multiple years over. Not as like designing a new system with this, but hey, the system is selling great so it's doing well, and it'll continue.
VS: That would imply, although not official, you're not entirely ruling out that we could see refreshed chips with a new naming scheme or something like that?
Ben: You know, in our naming schemes, we want to make it easy for customers to decide. Sometimes we look at a refresh like the 200 Series. That is largely a refresh product line. That's not brand new. But the reason is, it's really weird for a customer to have a 300 Series, an 8000 Series, and wonder... wait 8000 is less than 300, that doesn't make sense! So that's part of the reason.
In the current generation, we want the branding to be consistent and easily understood. Now it's basically that entire three-digit brand, higher number better. So, 200 is Hawk, and then, you know, in 300 you get Strix Point and Kraken, and the Max all the way at the top. That's a consistent brand strategy. I think we will do something in that domain for the Fire Range launch as well.
VS: I mean, admittedly, it's uh not always easy to pronounce the whole name of the chip in one sweep "Ryzen.AI.9.300.Max.Plus"!
Ben: I think several of us, you know, well, let me just say about in the AMD domain we have so many products, so it's tough. We want something be consistent, we want it to be differentiated, we want consumers to know. So, honestly, when a consumer walks into retail, I think they're seeing Copilot+ and they're seeing 9, 7, 5, 3. That's likely... that's enough. They're not looking at the exact model number.
We're all (referring to enthusiasts) kind of like very inside baseball, right? You wanna know every detail, so I think that's part of the differences.
VS: And do you see prospects for RDNA 4 laptops going ahead? Unfortunately, the number of AMD dGPU-based laptop SKUs have been pretty anemic.
Ben: Our current graphics strategy is focused on the desktop market with RDNA 4. So, I think you'll see those types of products first in the future. Certainly, RDNA 4 and future graphics technologies will make it into mobile, whether they be on APUs or future products.
VS: Probably this is futuristic, but we've heard stuff like RDNA and CDNA would be combining together.
Ben: Yes, so that is a long-term project to unify the two, and I'm actually personally very excited about that because the ML focus is actually where the client market is going to go in the long term. So having that, um everybody going in the same direction, you know, I think would be a real positive.
VS: Okay, so one final question, and this has been one of my pet peeves as well. At the low end I think there is a lot of scope because not everybody would want a very high-end chip for their needs. Stuff like basic 1080p editing, most chips can do it right now. Why isn't AMD focusing on, say a Ryzen 3 because, you know, you're offering a 50 TOPS NPU across the stack. Why not do the same on the GPU side? Or maybe leverage the NPU itself and give us an entry-level product on which you can do basic content creation and stuff.
Or go may be even lower. Like you know, there was something called the Ryzen Embedded R1606G, which we saw in the odd mini PC or two.
Ben: So, we do have plans to bring the NPU to better price points in the market over time. I think the industry is heading that way as well. So absolutely, we want to offer every consumer a Copilot+ PC, NPU-enabled AI-enabled experience. You just have to look at the economics and price points that those command, and it's just a silicon area, okay, what can we put on there.
Like, we could drop the memory interface to 64-bit. But what does that do to the rest of the system? How many cores are a minimum for this type of performance? I guess I'll say in the last two years, the NPU has become not a side. It is one of the three of the trinities of the IPs that we need to focus on. So, we are absolutely trying to right-size those three across all of the segments.
Source(s)
Own
