Free, open-source DeepSeek V3.2 Exp AI LLM debuts with lower compute costs, helping businesses save even more money

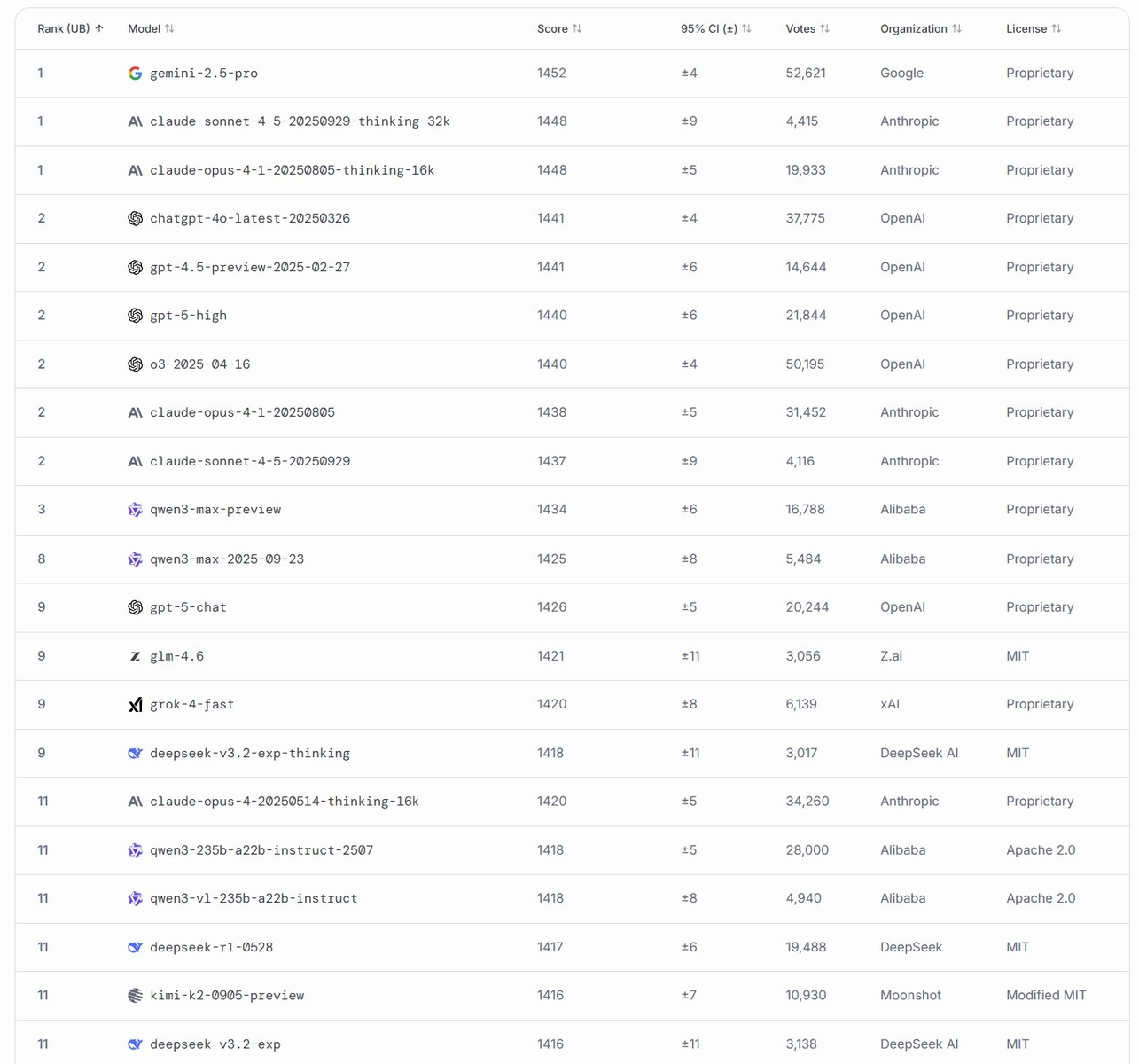
DeepSeek has released its latest artificial intelligence large-language model, DeepSeek-V3.2-Exp, with significantly reduced compute costs. This optimization helps businesses who use the company’s API in their apps save money while providing access to a smart AI, which has ranked 11th among the most powerful LLMs released worldwide.
This was achieved by using a new DeepSeek Sparse Attention (DSA) design to focus on indexing tokens not with every other token, as is the case with traditional AI transformers, but only with the most relevant ones. This allows the AI to process input text faster up to its 128K-token window with less memory use.
App developers accessing DeepSeek V3.2 Exp via its public API can expect to pay over 50% less than for the previous version, while maintaining comparable performance across standardized AI benchmarks.
The 400 GB AI LLM can be downloaded from Hugging Face for free and run locally on powerful computers. Readers who do so will need a system with multiple Nvidia H100/H200/H20 GPUs or a single NVIDIA B200/GB200 server at minimum due to the model's 1.5+ TB VRAM requirement.
Readers who want to run DeepSeek v3.2 on home desktops will need to wait until quantized models are released on Hugging Face, such as this one for v3.1 by unsloth, and have a GPU with at least 24 GB of memory, such as this Nvidia 5090 on Amazon.

Source(s)
