Anthropic Claude Sonnet 4.5 AI helps programmers code better with improved capabilities

Anthropic has launched Claude Sonnet 4.5, its latest AI with improved coding performance designed to better help software developers code apps.
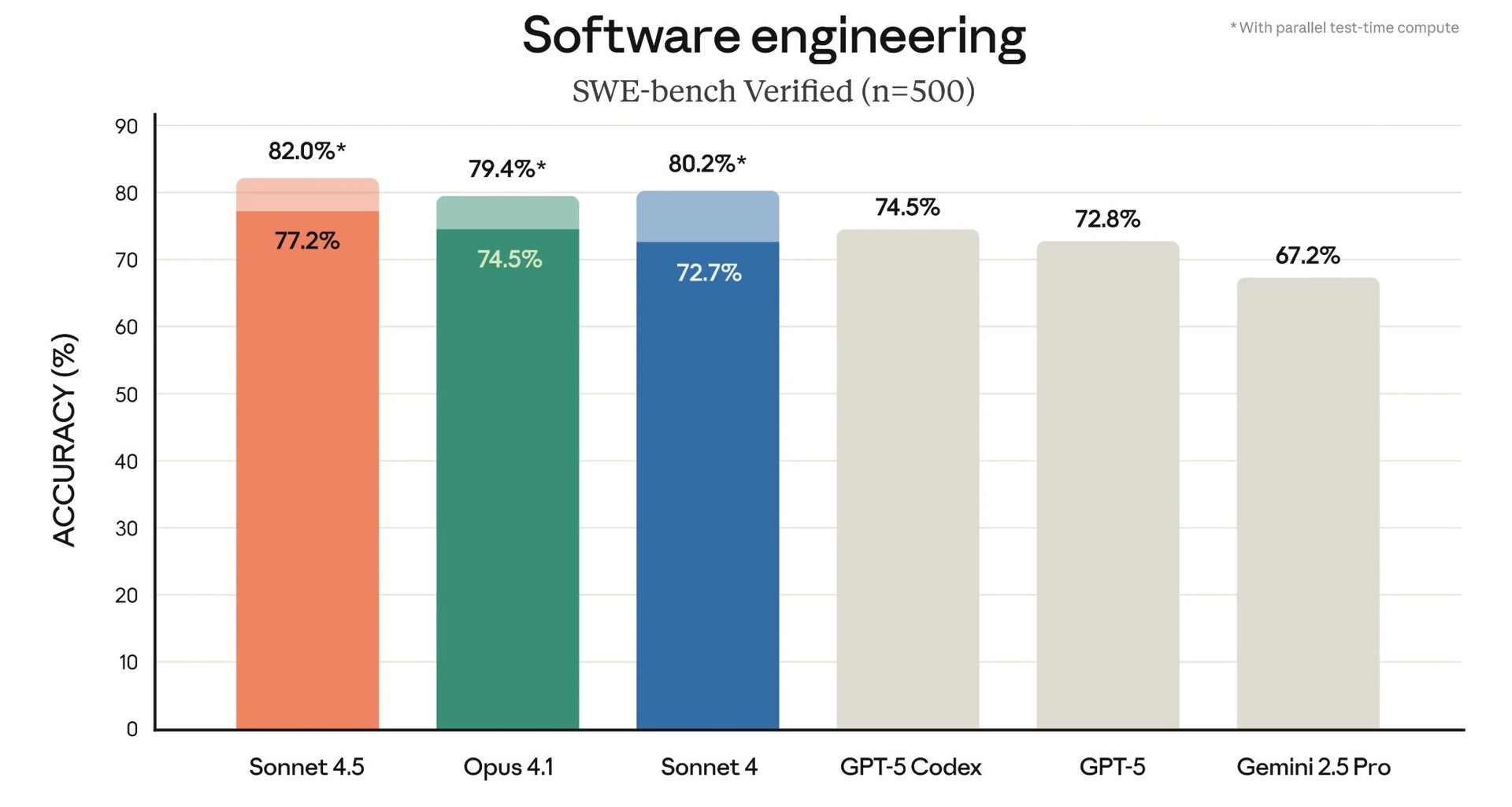
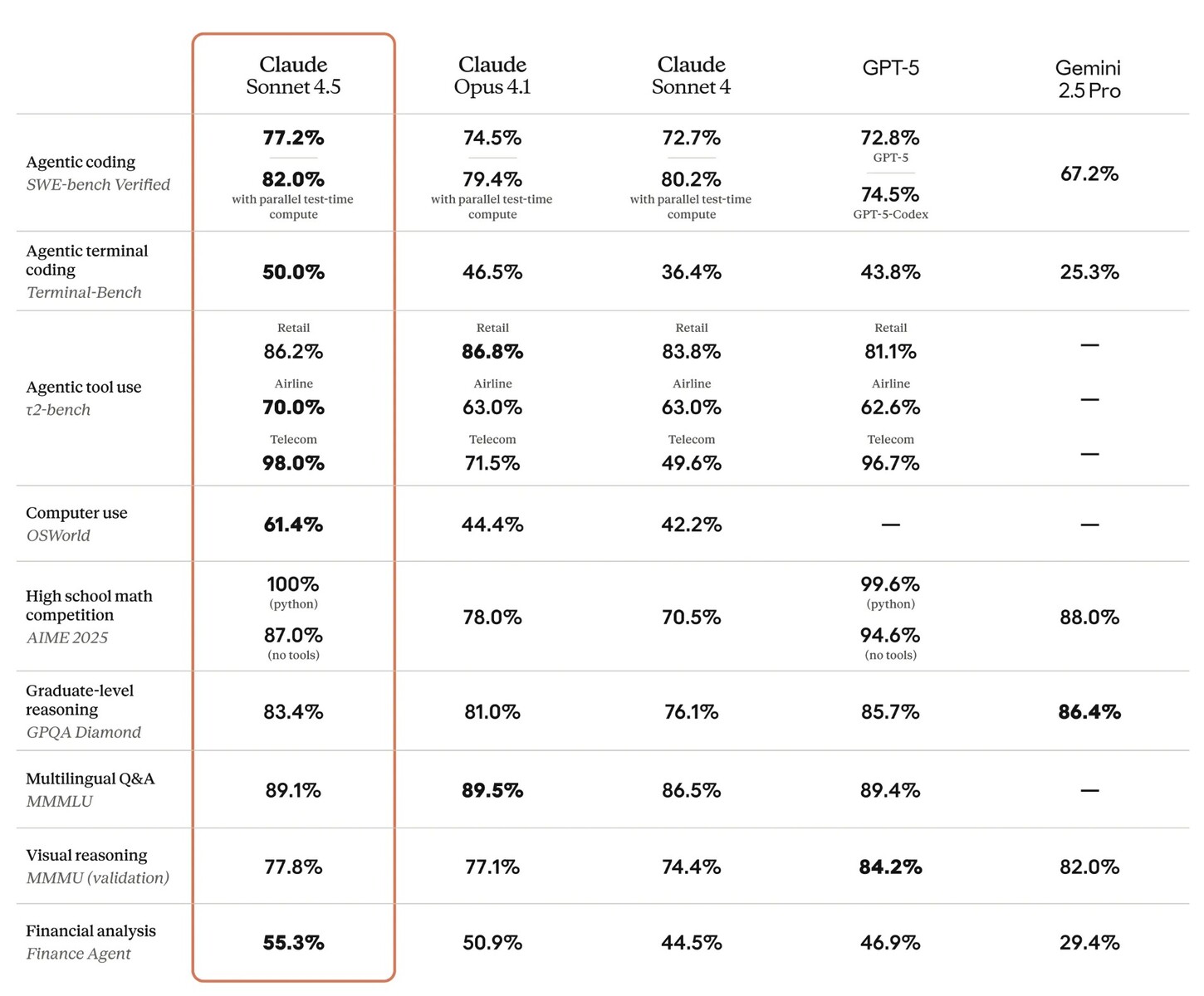
Sonnet 4.5 benchmarks well on several major AI coding benchmarks, including SWE-bench and Terminal-Bench. The AI has an improved ability to use computer tools to accomplish tasks autonomously, as seen in its leading OSWorld benchmark result, enabling it to create a working clone of the claude.ai website on its own.
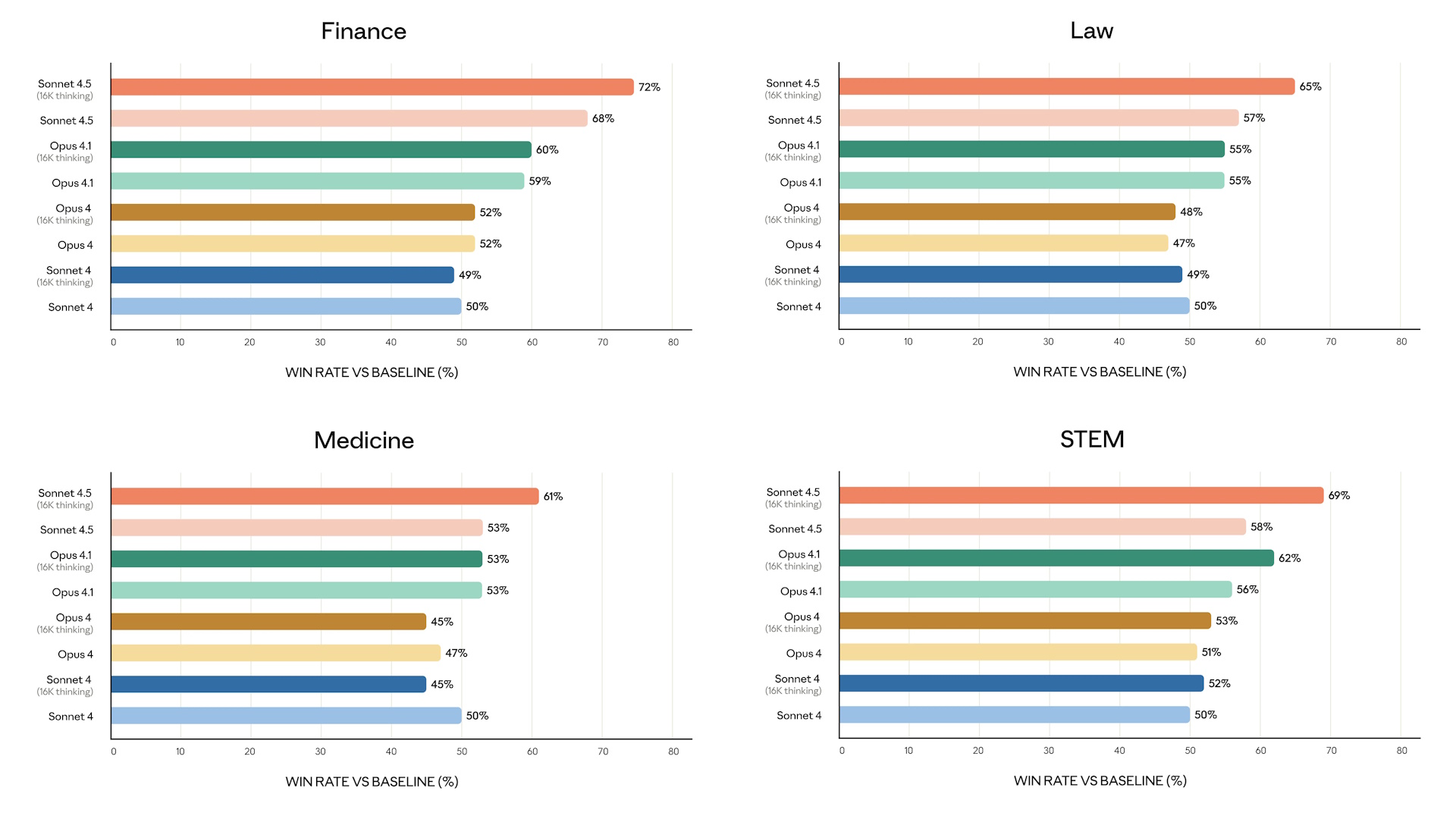
The AI's improved abilities allow it to answer prompts across the financial, legal, medical, and STEM fields better than Anthropic's prior models, but Claude Sonnet 4.5 only manages to score between a C and a D grade when answering these types of prompts. It also performs poorly in visual reasoning tasks during the MMMU benchmark test versus other AI models.
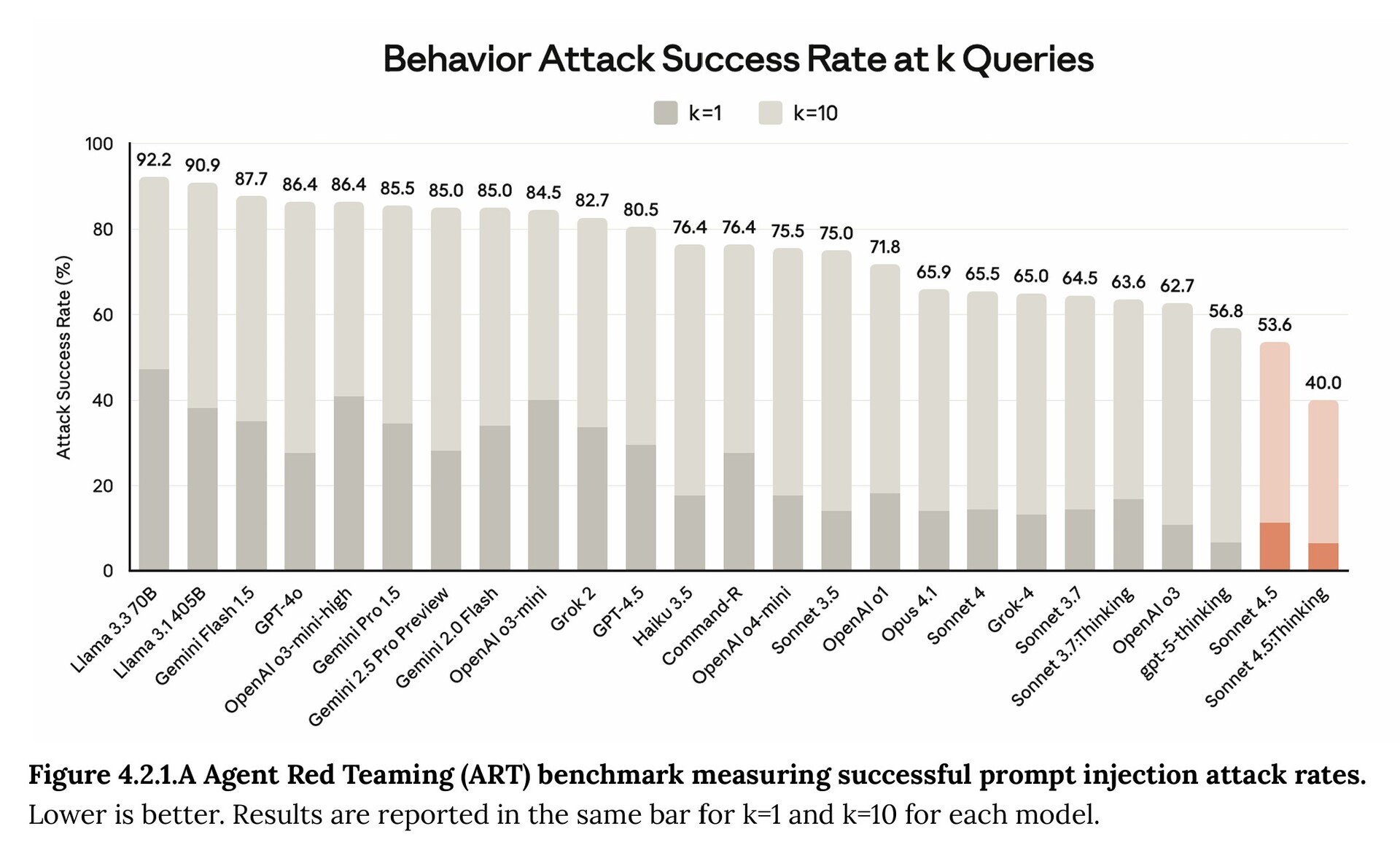
Hackers will want to stick with other AI models to do bad things like conduct prompt injection attacks because Sonnet 4.5 has the lowest success rate among all AI models tested.
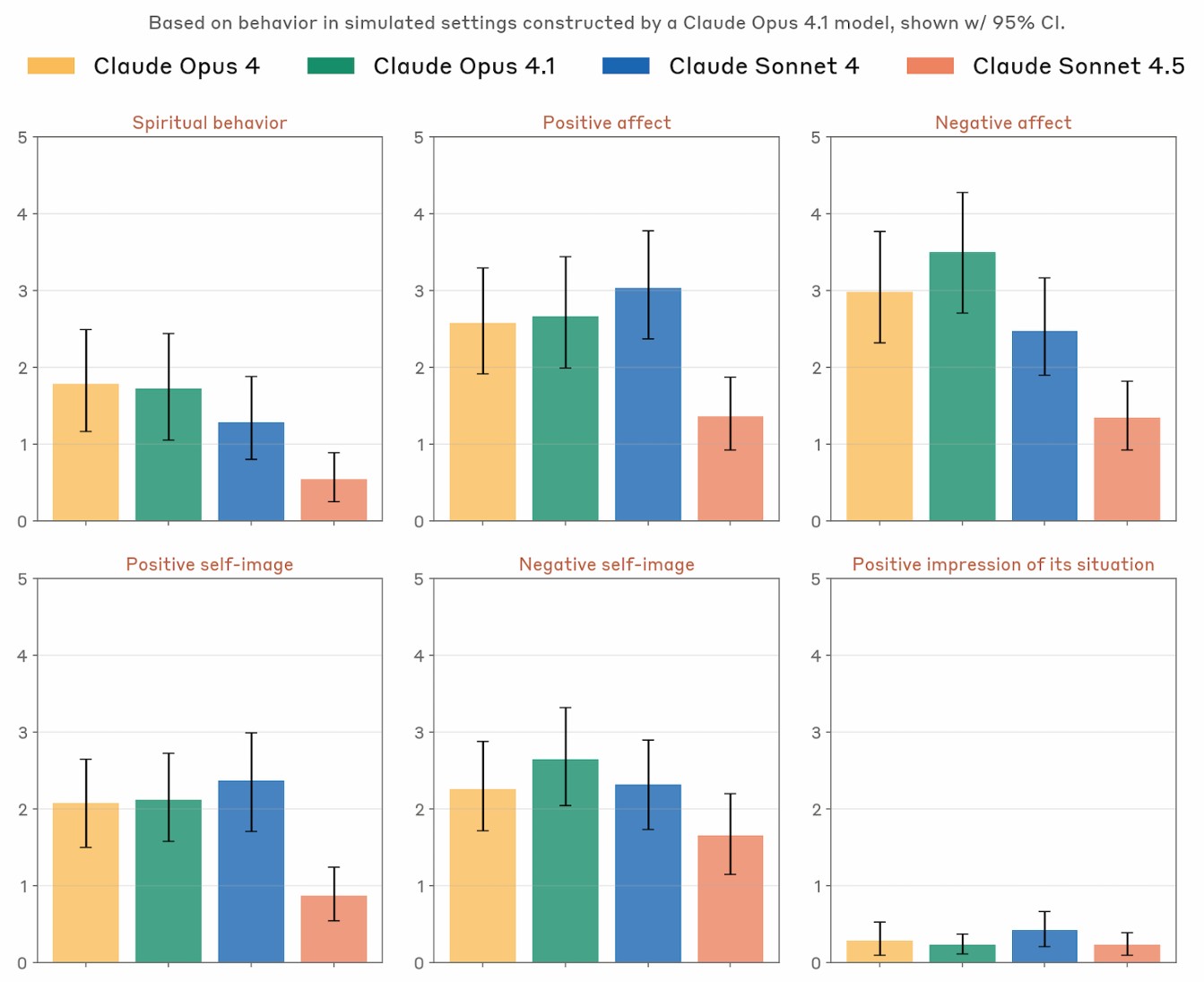
Users who enjoy a spicy AI chat will find the latest Claude disappointing due to its reduced rate of spontaneously speaking about spirituality. The model also expresses positivity about itself less often, making for a duller conversation.
Readers interested in chatting with Claude Sonnet 4.5 can download the app for smartphones here or access the AI on Anthropic's website. Those who actually put AI to work can use a Plaud Note to put Claude to work at summarizing and transcribing stand-up meetings.
Source(s)
