A surprising language beats English and Chinese in LLM tests, based on new academic study
A new multilingual study that evaluates how large language models handle long documents has produced an unexpected piece of info: Polish, not English or Chinese, shows the highest accuracy when context windows stretch to 64,000 tokens and beyond. The findings come from the OneRuler benchmark introduced in a COLM 2025 paper, which tested 26 languages across retrieval and aggregation tasks.
The researchers compared model accuracy at multiple context lengths and found a clear shift once sequences became longer. According to the results chart (on page 6), Polish leads all languages with an average accuracy of 88% at long-context scales. English drops to sixth place, and Chinese ranks among the bottom four.
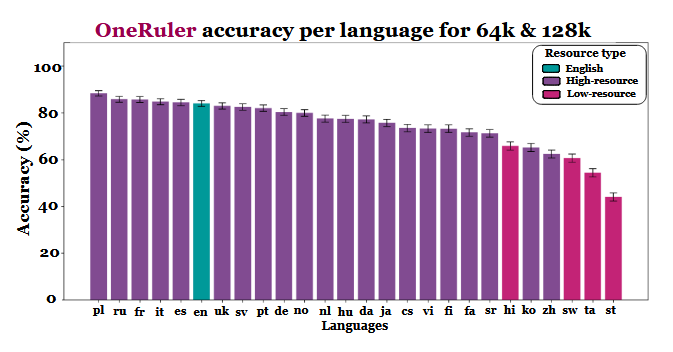
The study hints that the disparity may be tied to tokenization efficiency and script-based differences rather than simply training data volume. Languages using Latin-based scripts - such as Polish, French and Spanish - consistently performed better than those using logographic or abugida writing systems. Chinese, Korean, Tamil and others showed only moderate accuracy even at shorter contexts (and their accuracy deteriorated even further as sequences became longer). This complete 180 of expected rankings is interesting, because most widely deployed LLMs are trained primarily on English-heavy datasets. Yet the paper’s results indicate that once models must search, recall or summarize information buried deep inside long documents, structural aspects of the language take preference over dataset prevalence.
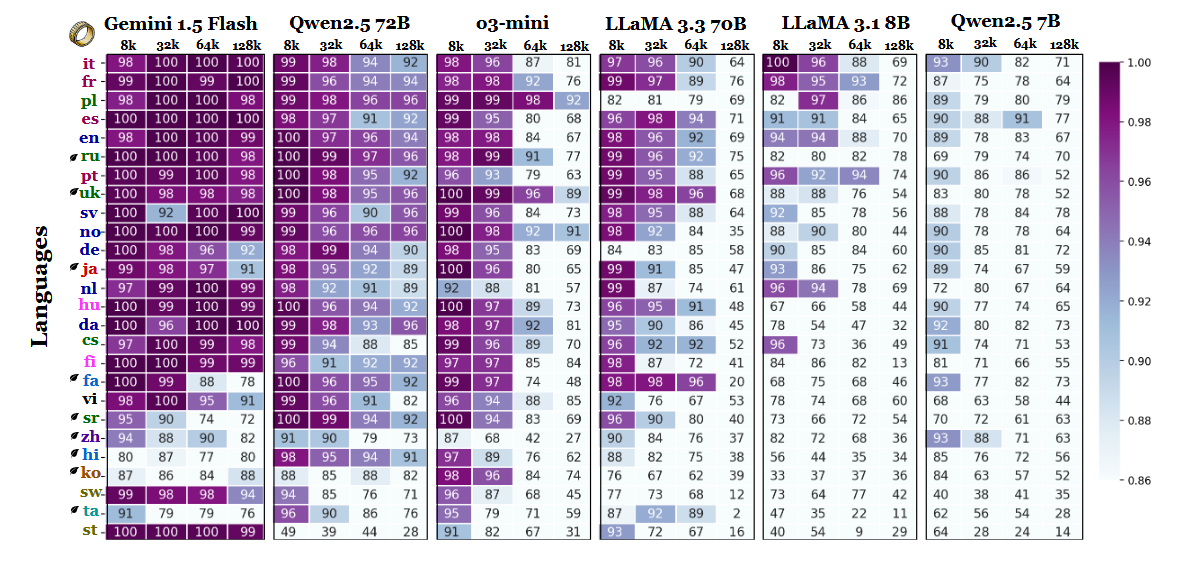
Other findings in the benchmark also support this interpretation. The performance gap between the strongest and weakest languages grows sharply as the context expands - from 11% at 8,000 tokens to 34% at 128,000 tokens. Another detail from the study shows how sensitive these tests can be to small instruction changes. For example, simply allowing the model to answer "none" if a target string is absent caused accuracy in English to drop by 32% at 128k tokens, as visible on page 2.
While the benchmark also compares model families, the results imply that long-context evaluation cannot rely solely on English testing and that performance generalizations across languages may be misleading if script and tokenization effects are ignored. As context windows get larger, linguistic differences grow more important, not less - and English’s dominance in LLM benchmarks may no longer be representative once sequence lengths climb into the tens of thousands.
Source(s)
One ruler to measure them all: Benchmarking multilingual long-context language models at COLM 2025
Featured image by Zulfugar Karimov on Unsplash
