Nvidia Pascal Architecture Overview
Pascal was introduced by Nvidia during the GTC 2016 in April in the big GP100 chip. Currently, the latter will only be used for the professional Tesla P100 card for servers. We will see the first consumer version, the GP104, in the GeForce GTX 1080 and 1070 sometime in May. These chips are manufactured in a new 16 nm FinFET process by TSMC, which is already a big improvement over the old 28 nm GPUs. The later announced GeForce GTX 1050 Ti and 1050 are produced in 14 nm FinFET at Samsung.
The micro architecture of the Pascal chips is an advancement of Maxwell and still has a big focus on efficiency. It is a modular design and can be used in tablets (Tegra, not yet confirmed) all the way up to large server graphics cards (Tesla with the GP100). Depending on the model, it can use from 1 up to 60 Streaming Multiprocessors (SM), which can vary slightly. The top model GP100 (for servers) gets 64 cores per SM. There are also additional dedicated "Double Precision" (DP) units. The smaller versions for desktops and notebooks waive the DP units and get 128 cores per SM instead.
The GP104, which will be used for the GTX 1080 and GTX 1070, for example, is equipped with four GPCs (Graphic Processing Clusters), 20 Streaming Multiprocessors (SMs) and 8 memory controllers (=256-bit). Each SM has 128 (CUDA) cores, 256 KB Register File Buffer, 96 KB Shared Memory unit, 48 KB L1-cache and 8 texture units.


Nvidia has announced the following differences between Pascal and Maxwell:
Improved Efficiency
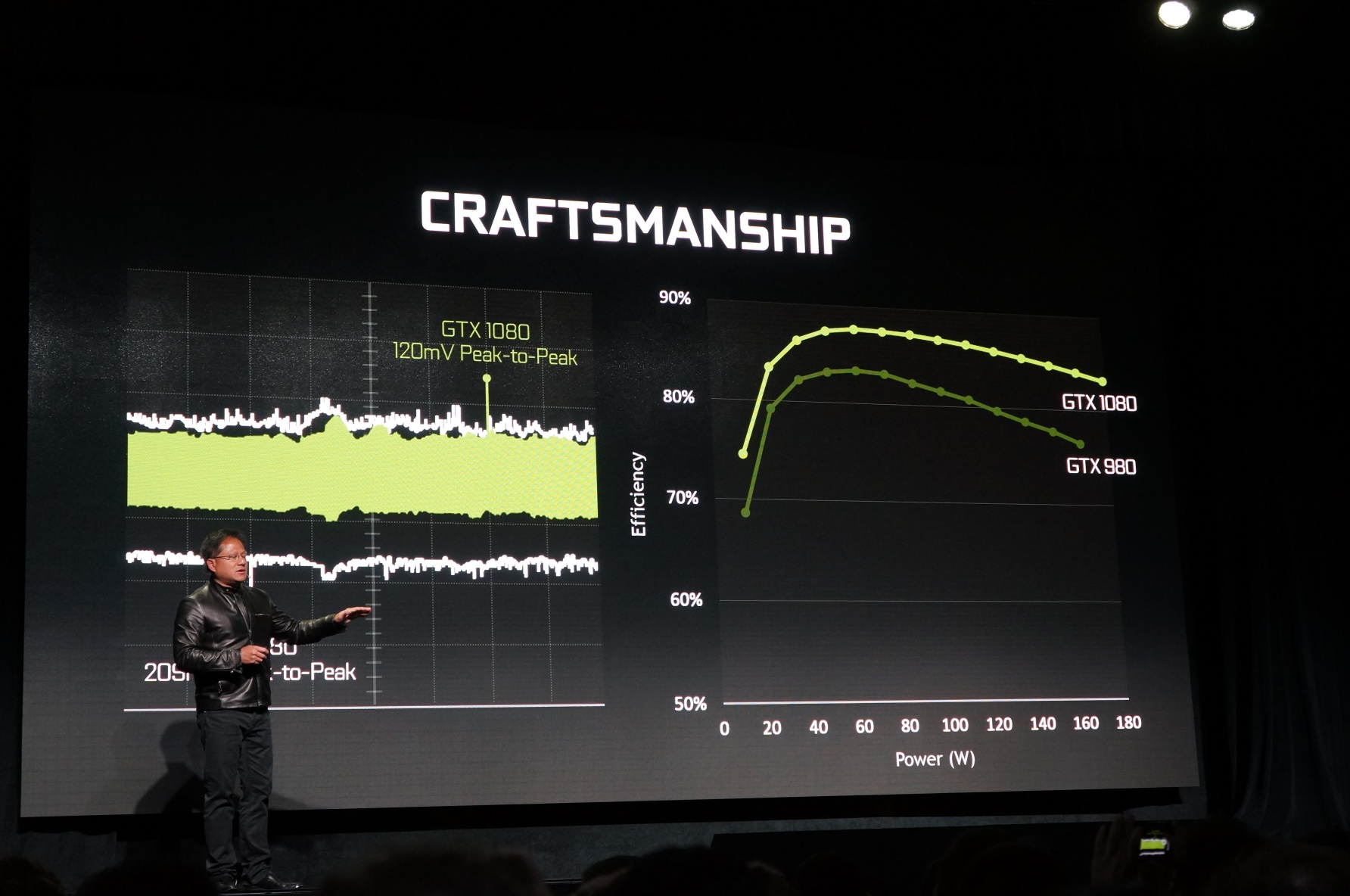
Thanks to the move to the new 16 nm FinFET process and internal improvements, the efficiency has once again clearly increased compared to Maxwell. The following slides show that Nvidia has improved efficiency significantly in all ranges of the power consumption, particularly in higher regions.
Architectural Optimizations for Higher Clocks
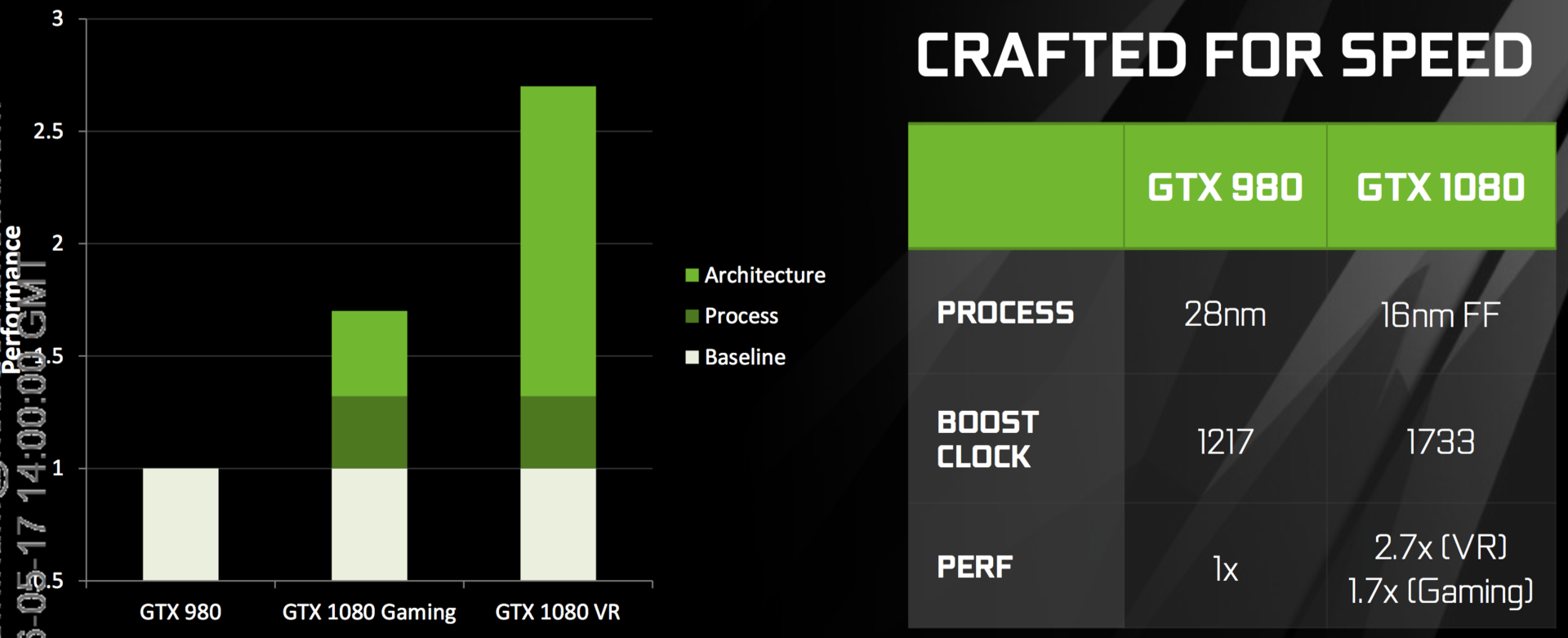
The example is once again the desktop GTX 1080. It can easily be overclocked to over 2 GHz via air-cooling and the clock is therefore much higher compared to the old GTX 980 (1216 MHz without overclocking). By default the clock of the 1080 is already 40% higher than the GTX 980. Much more than a result of the 16 nm process alone, according to Nvidia.
There were also adjustments to the chip and board design for the fast GDDR5X memory in the top models.
Improved Memory Compression
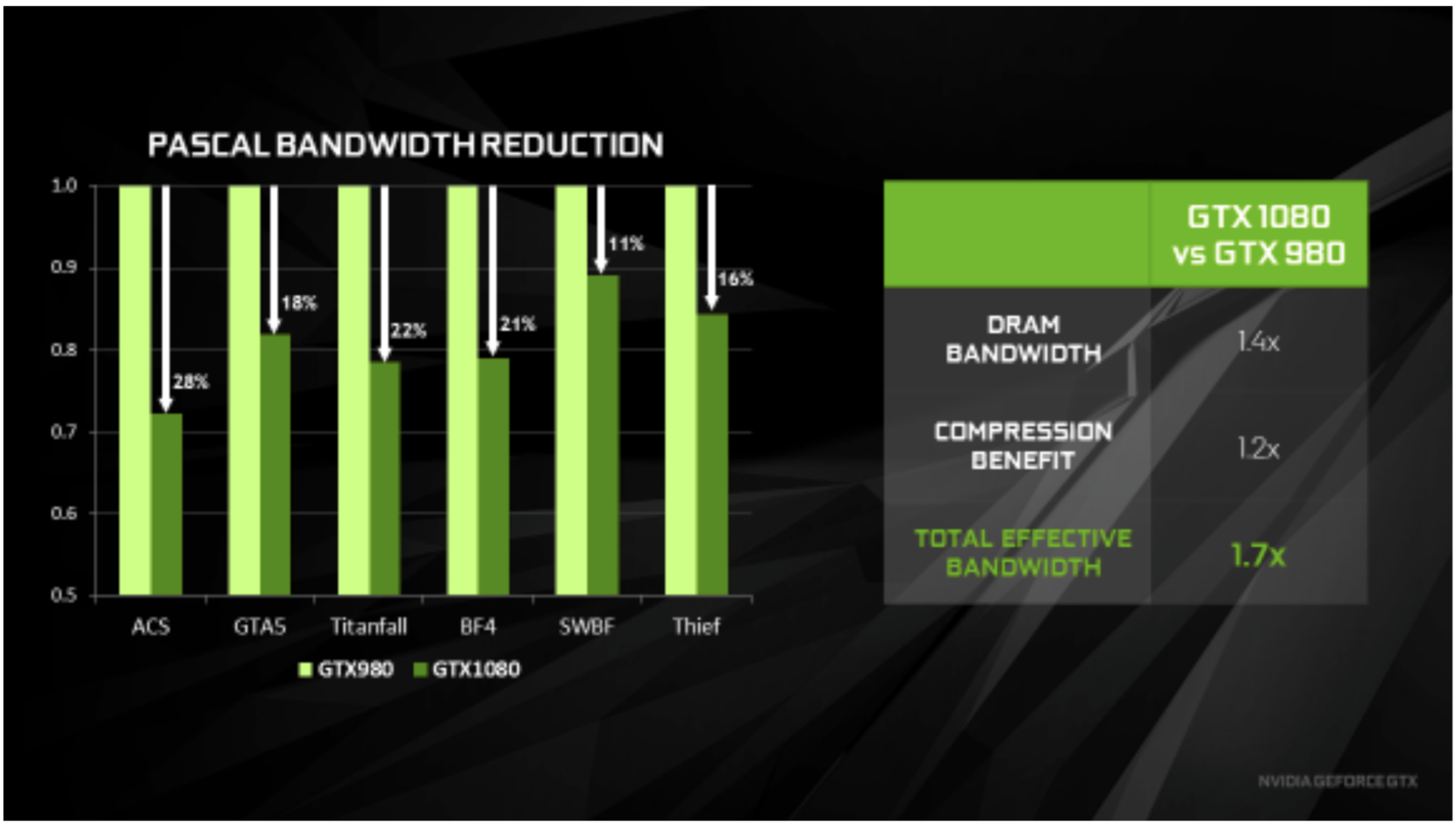
As well as an improved 2:1 compression, the fourth generation of the Delta Color Compression can also compress 4:1 and 8:1. The chip can also automatically try different kinds of compression and select the best. On average this improves the compression by a factor of 1.2x compared to the GTX 980 during gaming (which was selected by Nvidia). In combination with the higher bandwidth of the GDDR5X VRAM of the GTX 1080, we even get a 1.7x memory bandwidth increase.

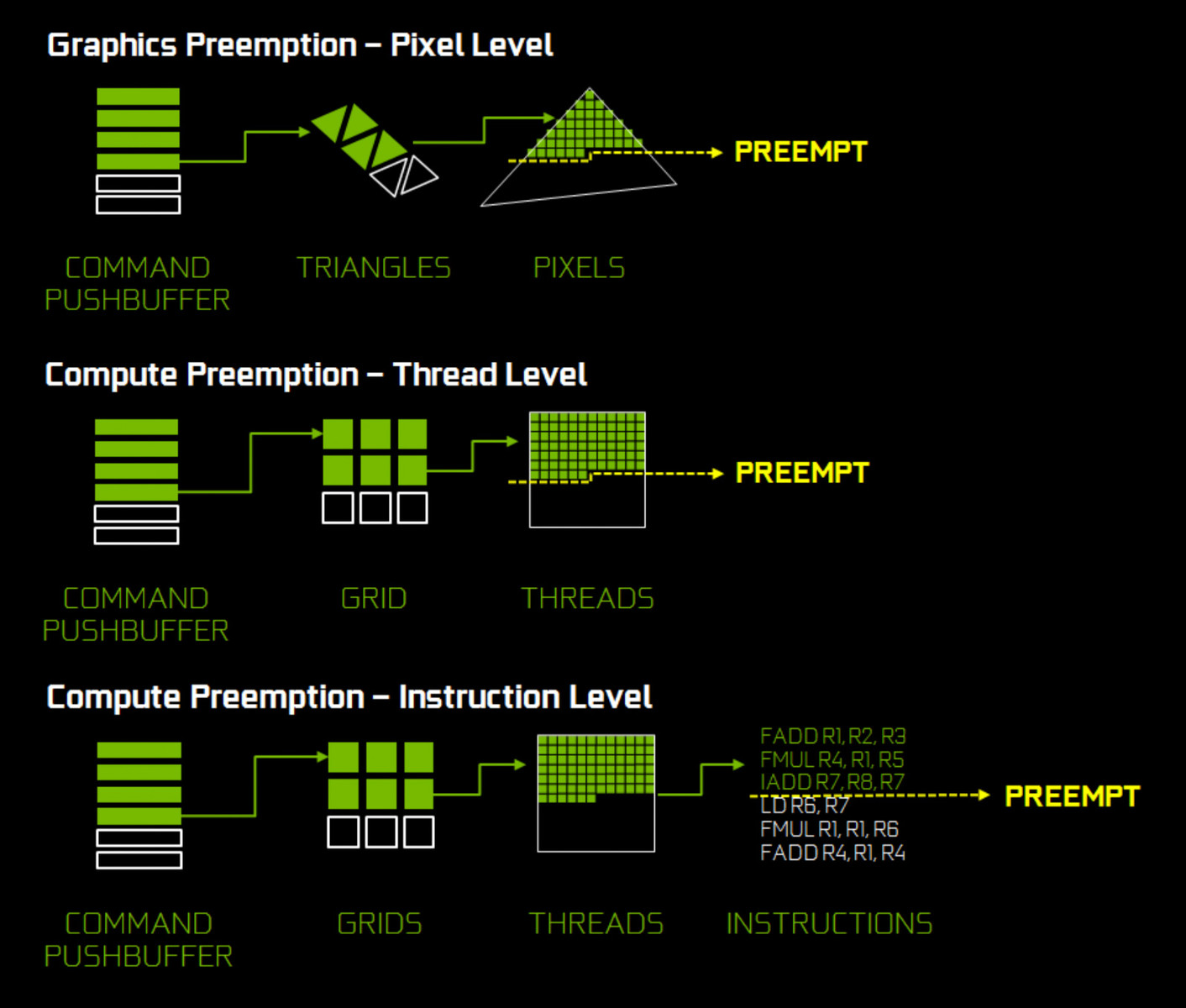
Improved Asynchronous Compute Support
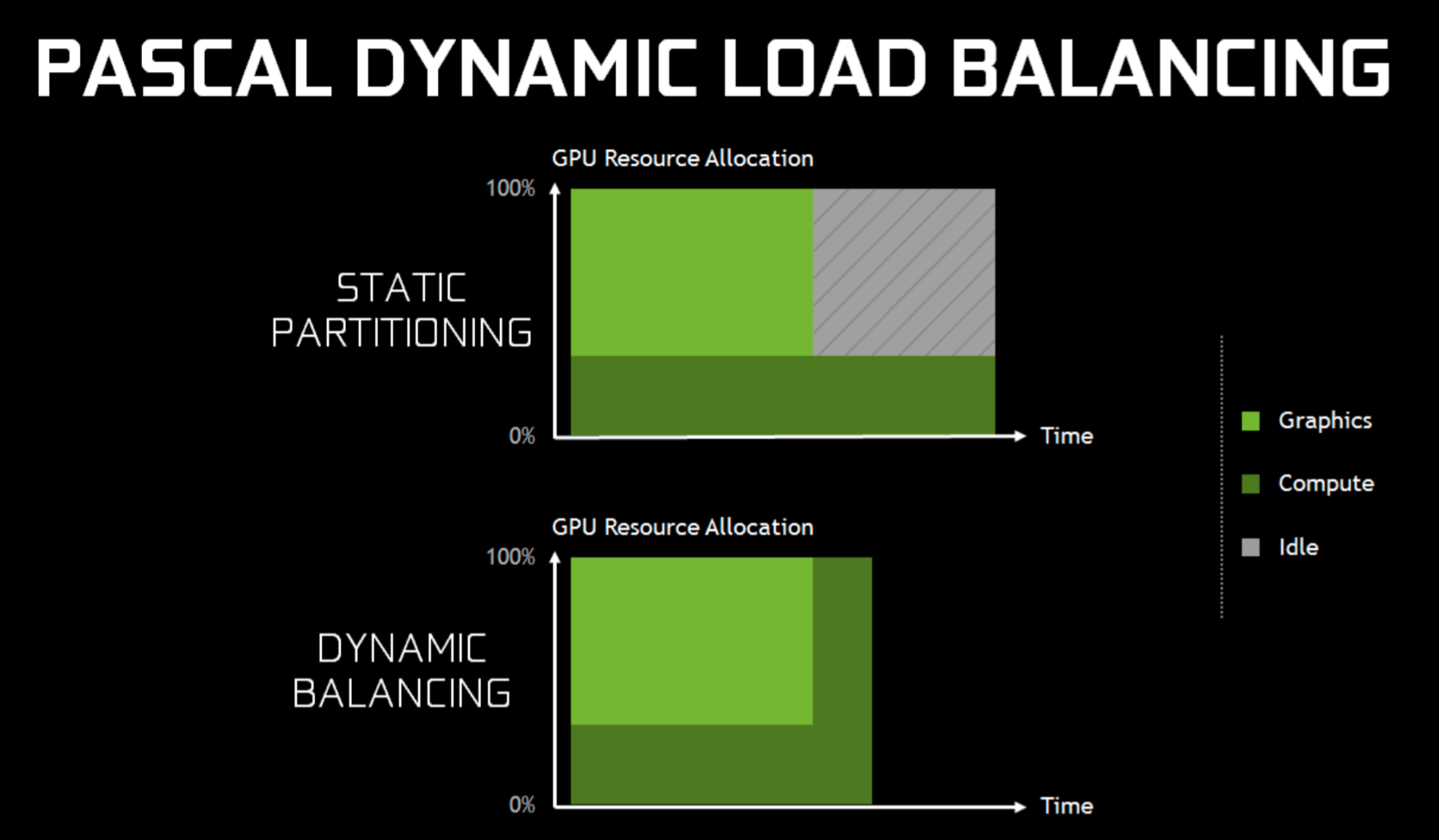
In Maxwell generation GPUs, overlapping workloads (compute and graphics) were implemented with static partitioning of the GPU. However, this partitioning could only be changed after both workloads were completed. If one of the two workloads was completed before the other, the remaining one could not utilize the whole GPU performance, but was limited to the allocated part. This allocation is now dynamic with Pascal and can therefore utilize all the GPU resources.
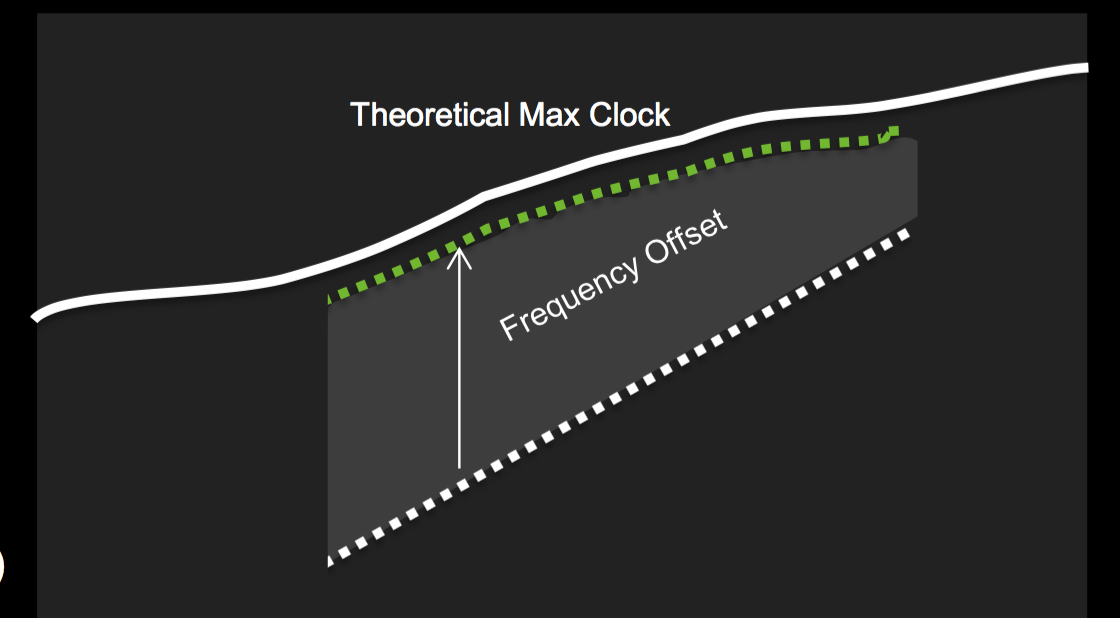
GPU Boost 3.0
GPU Boost can increase the clock of the GPU until it hits a predetermined temperature target. In addition to many other Boost refinements, GPU Boost 3.0 now features custom per-voltage point frequency offsets. You can find the perfect curve for each voltage point for each card via (third party) scanners and therefore select higher Boost clocks (overclock the GPU).
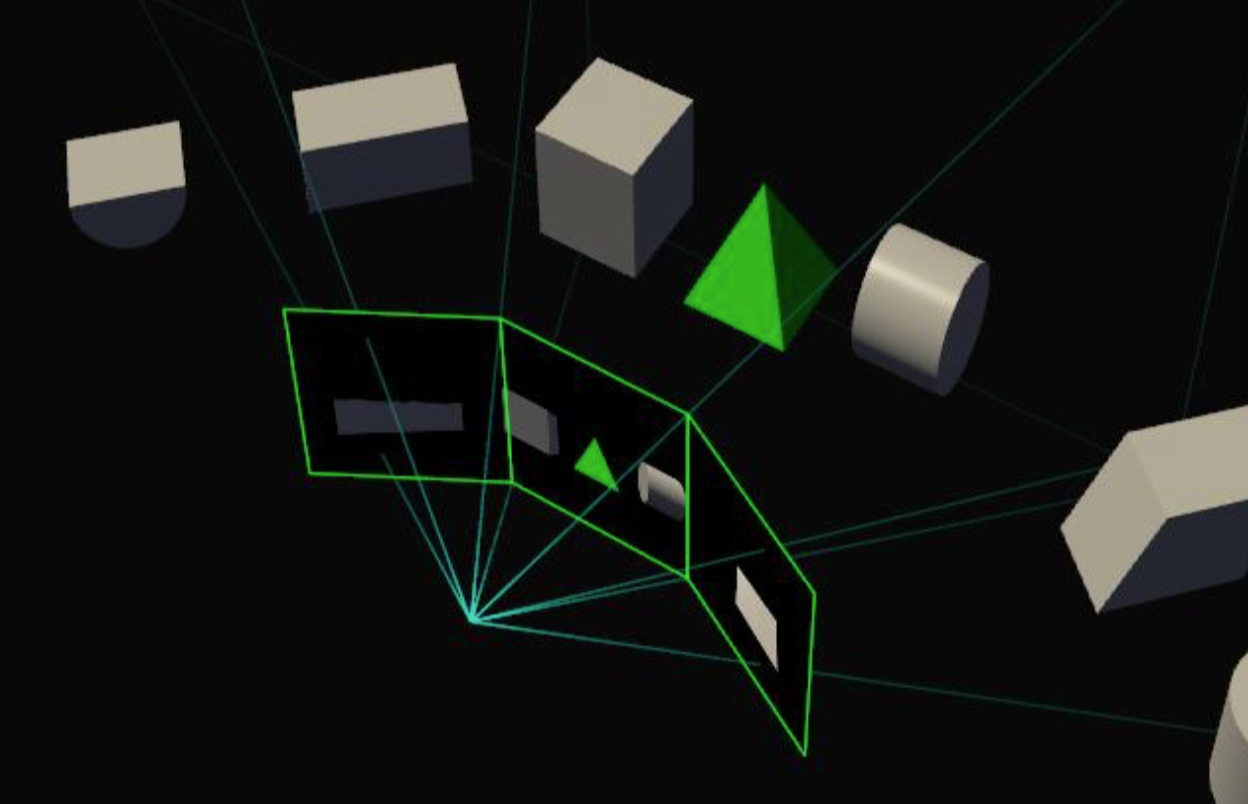
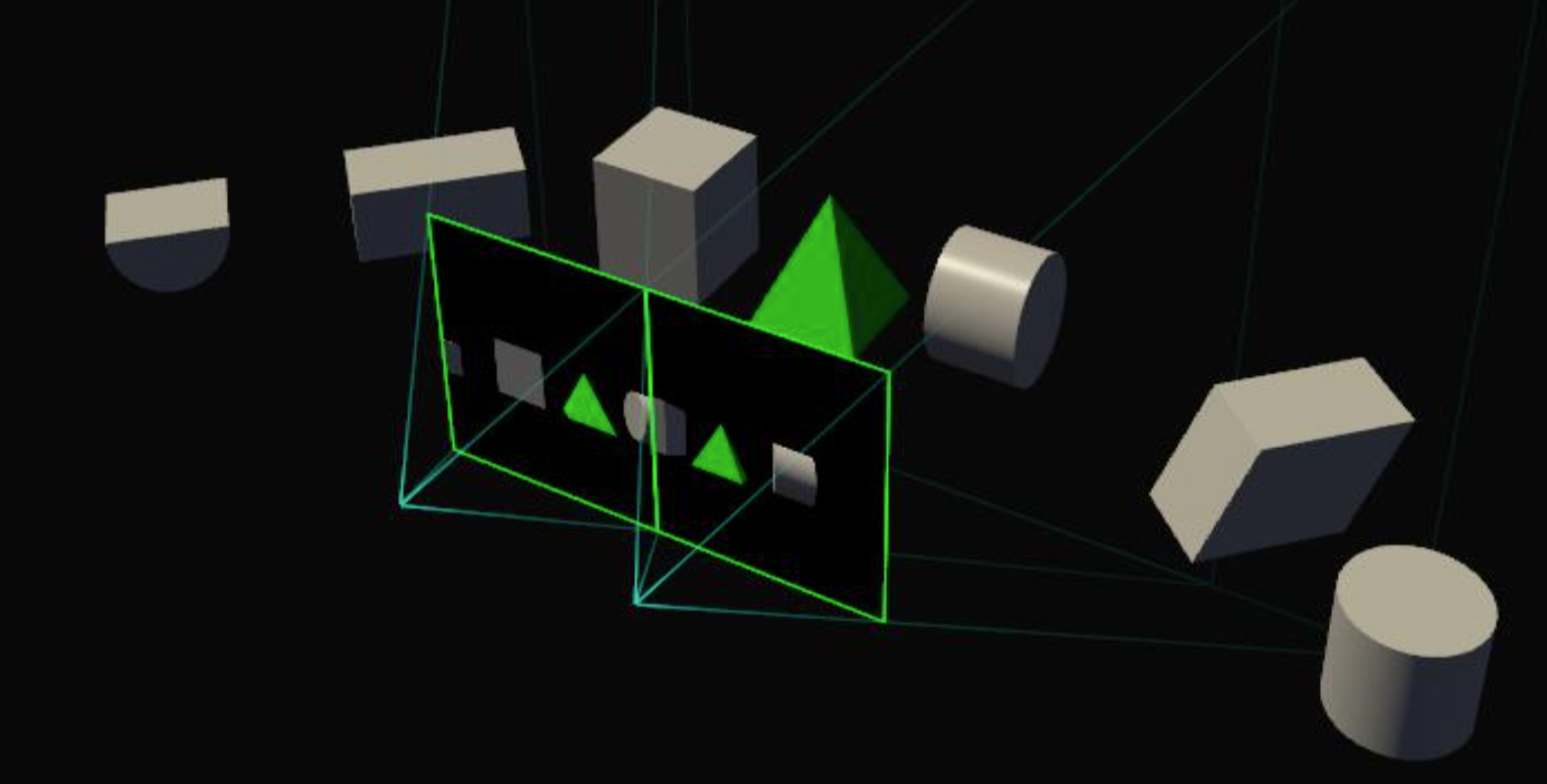
Simultaneous Multi-Projection
The Simultaneous Multi-Projection block is a new hardware unit, which is located inside the PolyMorph Engine at the end of the geometry pipeline and right in front of the Raster Unit. As its name implies, the Simultaneous Multi-Projection (SMP) unit is responsible for generating multiple projections of a single geometry stream. It can calculate up to 16 different projections at the same viewpoint and two with different distances on the x-axis. This technology can, for example, be used for multiple monitoring with different display angles, VR headsets or curved monitors.


Video Features and Display Ports
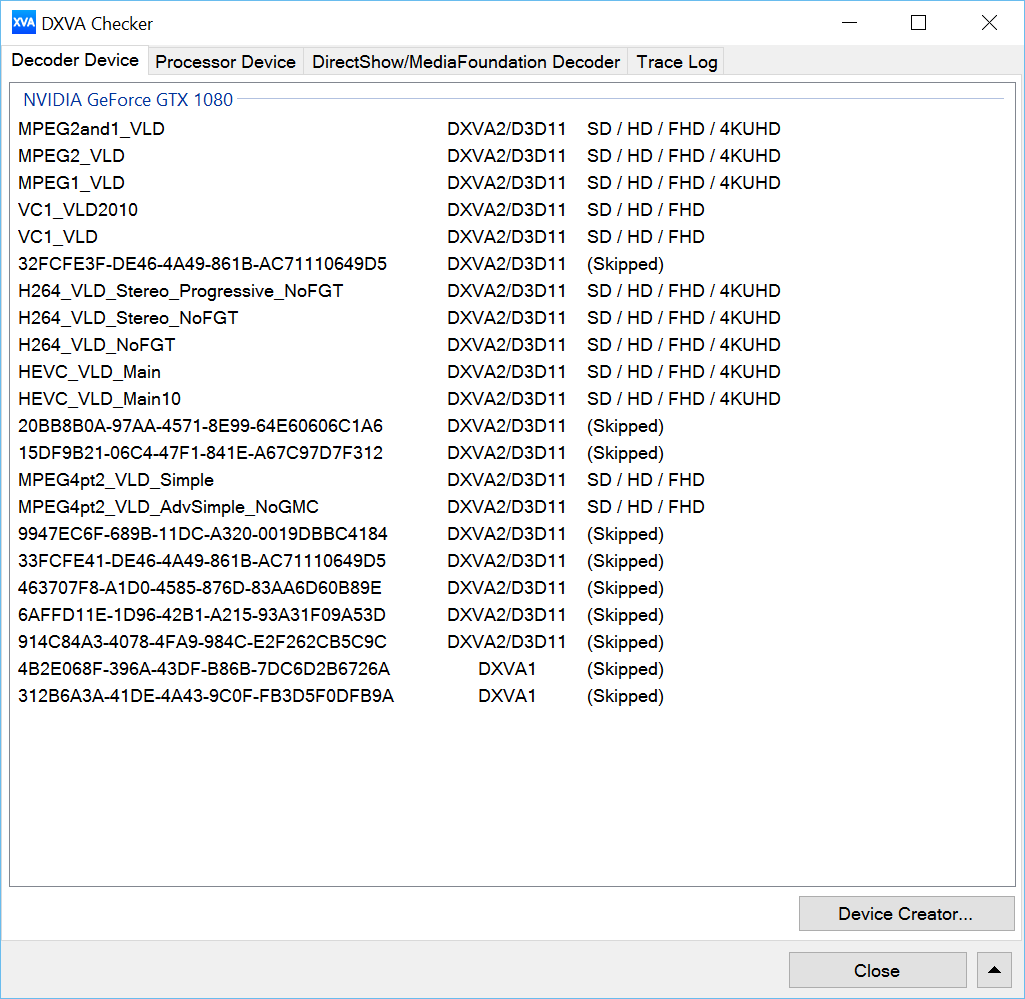
Pascal has also introduced improvements in terms of video features. The GP104 can now encode 10-bit HEVC and decode 10-bit and 12-bit HEVC. Even VP9 video playback is also accelerated by the hardware (4K 120 Hz 320 Mbps). In combination with additional security hardware, for the first time Pascal is certified as PlayReady 3.0 (SL3000) and therefore enables the 4K Netflix playback in Windows 10, for example. Another new feature is the HDR support for HDMI 2.0b and DisplayPort 1.4 (first TVs are already available, monitors are expected in 2017).
The GP104 GPU can still drive four monitors simultaneously, but the HDMI 2.0b (Maxwell HDMI 2.0) and DisplayPort 1.4 ("Ready", up to 7680x4320 @ 60 Hz via two DP 1.3 ports) are new features.
| GTX 980 (Maxwell) | GTX 1080 (Pascal) | |
|---|---|---|
| H.264 Encode | Yes | 2x 4K @ 60 Hz |
| HEVC Encode | Yes | 2x 4K @ 60 Hz |
| 10-bit HEVC Encode | No | Yes |
| HEVC Decode | No | 4K @ 120 Hz / 8K @ 30 Hz up to 320 Mbps |
| VP9 Decode | No | 4K @ 120 Hz up to 320 Mbps |
| 10-bit and 12-bit HEVC Decode | No | Yes |
Summary
Nvidia's new Pascal architecture is not just a simple Die-Shrink of the successful Maxwell architecture, but also introduces numerous optimizations and new features. Our performance tests of the desktop GTX 1080 confirm the performance and efficiency increase of the new generation. Simultaneous Multi-Projection is focused on virtual reality. GPU Boost 3.0 helps to get more performance from the GPU with overclocking. The improved efficiency and video features, however, will also be beneficial for the notebook chips.
Sources: Nvidia press event, Pascal White-Paper and Review Guide, Inside Pascal Blog Post (GP100)
